

在上个月举行的 HotChips 33 上 ,IBM 公布了其下一代 Z 系列处理器 “Telum”。 这款处理器采用了全新的内核架构,针对 AI 加速做了优化。其配置了 8 核 16 线程,频率超过 5GHz, 采用了三星 7nm 工艺制造,核心面积为 530 平方毫米,集成了 225 亿个晶体管,拥有全新的分支预测、缓存和多芯片一致性互连。
IBM 的 Z 系列处理器以拥有大型 L3 缓存而出名,并有单独的全局 L4 缓存,可作为多个处理器之间的缓存。不过在 Telum 上,不但没有了 L4 缓存,而且 L3 缓存也没有了。要知道无论英特尔还是 AMD, 现在都尽可能增大 L3 缓存容量或增加 L4 缓存以提高性能,比如在 AMD 采用 3D 垂直缓存 (3D V-Cache) 技术的 Zen 3 架构桌面处理器,为每个 CCD 带来额外的 64MB 7nm SRAM 缓存。

近日 ,Anandtech 发表了一篇文章,讨论了 Telum 的缓存架构。
现代的处理器普遍都有多级缓存,至于为什么会这样,可以看我们《超能课堂 (133): 为什么 CPU 缓存会分为 L1、L2、L3?》大概了解一下。简单来说,越靠近执行端口的缓存越小但越快(比如 L1), 缓存越多且越大那么访问所需的周期就越长(比如 L3)。 缓存除了大小,延迟也很重要,通常缓存越大延迟越大,缓存命中率也会更低。
为了更有效利用缓存,芯片设计公司需要分析这款处理器将用于哪方面的工作负载,以提高设计的效率 。IBM 的产品一般都是大型主机使用,大多是政府或银行这样的客户,对安全性和稳定性极高,这些产品都有故障安全和故障转移功能。
IBM 在上一代 Z15 产品上,基本单元是一个由五个模块构成的系统,其中四个是计算模块 (CP), 一个是控制模块 (SC)。 四个计算模块每个有 12 个内核和 256MB 共享的 L3 缓存,核心频率为 5.2 GHz, 面积为 696 平方毫米。四个计算模块两两配对,各自与控制模块相连。控制模块拥有 960MB 的 L4 缓存,并与四个计算模块共享 。Z15 采用了 IBM 和 GlobalFoundries 联合研发的 14nm FinFET SOI 特殊工艺制造 ,L1 和 L2 缓存与核心频率一样都是 5.2 GHz,L3 和 L4 缓存则是半速的 2.6 GHz。
这意味着单个 IBM Z15 系统是 25 块 696 平方毫米的芯片组成,共有 20 x 256MB 的 L3 缓存,还有 5 x 960MB 的 L4 缓存,以全对全拓扑连接。

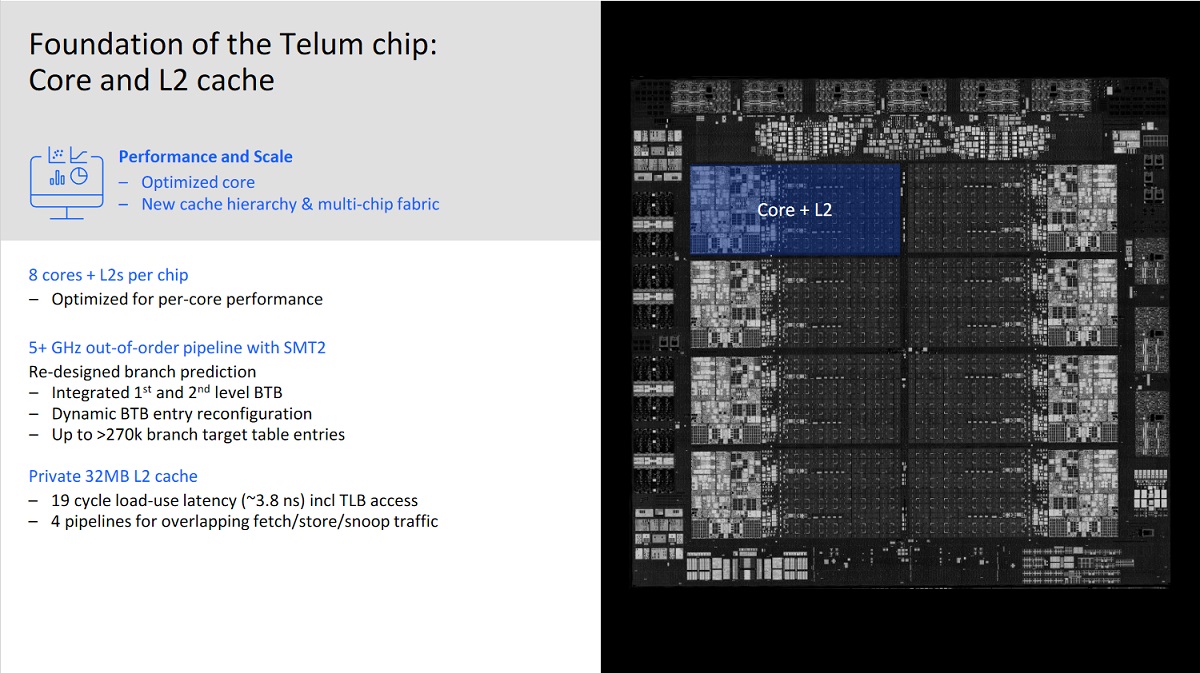
IBM 没有将新一代产品称为 Z16, 而且称为 Telum, 可能是因为对缓存的采用了不同的处理方法 。Telum 采用三星 7nm 工艺制造,单芯片拥有 8 个核心 。IBM 将两个芯片封装在一起,将四个同样封装的处理器组成一个单元,然后将四个同样的单元组成一个系统,整个系统共有 32 个芯片和 256 个核心。
IBM 为每个核心配置了 32MB 的 L2 缓存,这比一般的处理器大得多,而且取消了核心之间共享的 L3 和 L4 缓存。一般来说,这样的设计会使得缓存有很高的访问延迟 。IBM 采取的方法是,通过私有物理缓存里打造共享虚拟缓存的方法解决,意思是将平时需要放置在 L3 缓存里的部分标记为 L3 缓存线存在不同核心空余的 L2 缓存里。
L2 和 L3 缓存在物理上是一致的,可以根据工作负载的需要,包含来自不同核心的 L2 和 L3 缓存线的混合数据。这意味着一个芯片 8 个核心里 ,8 x 32MB 共 256MB 的 L2 缓存也可以视为“虚拟 ”L3 缓存,采用双向环形互连拓扑结构。
相似的方法 IBM 也用在了原来的 L4 缓存上 ,L2 缓存里也可以容纳 L4 缓存线。从单个核心的角度来看,在一个基于 Telum 打造标准的系统,可以访问 32MB 的 L2 缓存 ,256MB 的共享虚拟 L3 缓存,以及 8GB 的共享 L4 缓存 。IBM 表示,使用这种虚拟缓存的系统,每个核心的缓存相当于 Z15 的 1.5 倍,而且还改善了数据访问的平均延迟,性能提高了 40% 以上。
在具体运行中如何降低延迟和保证命中率是一个非常复杂的操作,加上功耗、缓存在断电和空闲等状态下如何保证单核心工作负载的一致性,这都是 IBM 需要考虑的问题。可以思考一下,如果 AMD 使用 3D V-Cache 技术堆叠的不是 L3 缓存,而是 L2 缓存,同样采取虚拟 L3 缓存线的方式,这样的微架构对性能会有怎样的影响?