

黄仁勋终于公布了NVIDIA新一代架构与核心,当然这次是面向HPC高性能计算、AI人工智能的“Hopper”,对应核心编号“GH100”,同时发布的还有基于新核心的加速计算卡“H100”、AI计算系统“DGX H100”。
与传闻不同,GH100核心采用的其实是台积电目前最先进的4nm工艺,而且是定制版,CoWoS 2.5D晶圆级封装,单芯片设计,集成多达800亿个晶体管,号称世界上最先进的芯片。
官方没有公布核心数,但已经被挖掘出来,和此前传闻一直。
完整版有8组GPC(图形处理器集群)、72组TPC(纹理处理器集群)、144组SM(流式多处理器单元),而每组SM有128个FP32 CUDA核心,总计18432个。
显存支持六颗HBM3或者HBM2e,控制器是12组512-bit,总计位宽6144-bit。
Tensor张量核心来到第四代,共有576个,另有60MB二级缓存。
扩展互连支持PCIe 5.0、NVLink第四代,后者带宽提升至900GB/s,七倍于PCIe 5.0,相比A100也多了一半。整卡对外总带宽4.9TB/s。
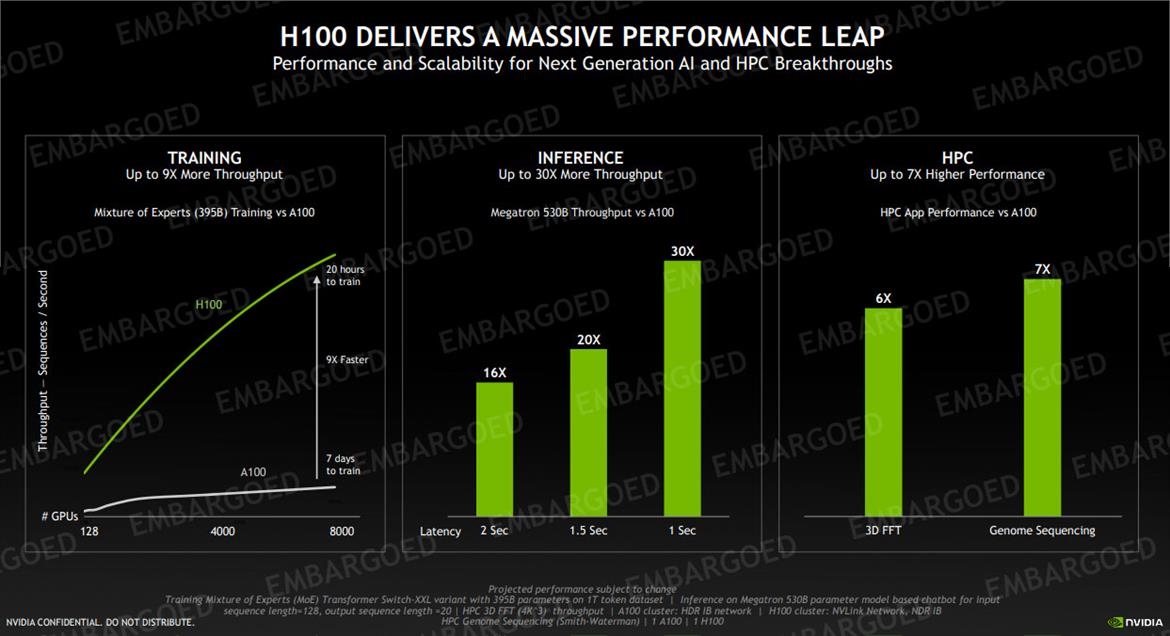
性能方面,FP64/FP32 60TFlops(每秒60万亿次),FP16 2000TFlops(每秒2000万亿次),TF32 1000TFlops(每秒1000万亿次),都三倍于A100,FP8 4000TFlops(每秒4000万亿次),六倍于A100。


H100计算卡采用SXM、PCIe 5.0两种形态,其中后者功耗高达史无前例的700W,相比A100多了整整300W。
按惯例也不是满血,GPC虽然还是8组,但只开启了66组TPC(魅族GPC屏蔽一组TPC)、132组SM,总计有16896个CUDA核心、528个Tensor核心、50MB二级缓存。
显存只用了五颗,最新一代HBM3,容量80GB,位宽5120-bit,带宽高达3TB/s,相比A100多了一半。

DGX H100系统集成八颗H100芯片、搭配两颗PCIe 5.0 CPU处理器(Intel Sapphire Rapids四代可扩展至器?),拥有总计6400亿个晶体管、640GB HBM3显存、24TB/s显存带宽。
性能方面,AI算力32PFlops(每秒3.2亿亿次),浮点算力FP64 480TFlops(每秒480万亿次),FP16 1.6PFlops(每秒1.6千万亿次),FP8 3.2PFlops(每秒3.2千亿次),分别是上代DGX A100的3倍、3倍、6倍,而且新增支持网络内计算,性能3.6TFlops。
同时配备Connect TX-7网络互连芯片,台积电7nm工艺,800亿个晶体管,400G GPUDirect吞吐量,400G加密加速,4.05亿/秒信息率。



DGX H100是最小的计算单元,为了扩展,这一次NVIDIA还设计了全新的VNLink Swtich互连系统,可以连接最多32个节点,也就是256颗H100芯片,称之为“DGX POD”。
这么一套系统内,还有20.5TB HBM3内存,总带宽768TB/s,AI性能高达颠覆性的1EFlops(100亿亿亿次每秒),实现百亿亿次计算。
系统合作伙伴包括Atos、思科、戴尔、富士通、技嘉、新华三、慧与、浪潮、联想、宁畅、超威。
云服务合作伙伴包括阿里云、亚马逊云、百度云、Google云、微软Azure、甲骨文云、腾讯云。



