Cayman Radeon HD 6900、Barts Radeon HD 6800两个系列虽然如此之近,但却基于两种截然不同的核心架构。Radeon HD 6800延续着R600以来的5D式流处理器设计,或者叫VLIW5,四个简单加一个复杂流处理器组成一个SIMD单元;Radeon HD 6900则改成了4D式设计,又叫VLIW4,每组SIMD单元包括四个均等的中型流处理器,外加一个通用目的光栅单元和一个分支单元。
除此之外,Cayman Radeon HD 6900核心还有更多SIMD阵列和纹理单元、双图形引擎、第八代曲面细分、改进的渲染后端、新的GPU计算能力、增强质量抗锯齿(EQAA)、带宽超过 5Gbps的高速256-bit GDDR5显存界面等等,下边我们会一一讲解。

VLIW4 4D式架构采用四路并发设计,所有的流处理器都具有相同的整数、浮点操作执行能力(不再有T-Unit),不过其中两个还是附加了一些特殊功能。
AMD宣称,VLIW4架构相比于VLIW5能将核心面积减少大约10%,同时简化调度和光栅管理,逻辑核心也得到了大范围的重新利用。
虽然家构图上没有标明Cayman Radeon HD 6900核心有多少个这种流处理器,但根据此前消息双芯的Radeon HD 6990会有3840个,那么顶级单芯Radeon HD 6970自然就是1920个了,也就是30个SIMD阵列引擎。

前端设计方面,Cayman Radeon HD 6900核心使用了两个图形引擎,每时钟周期可处理两个原语(Primitive),具备基于区块的负载均衡,转换和隐面消除率翻番。
同时两个光栅器单元,每时钟周期最多可处理32个像素;
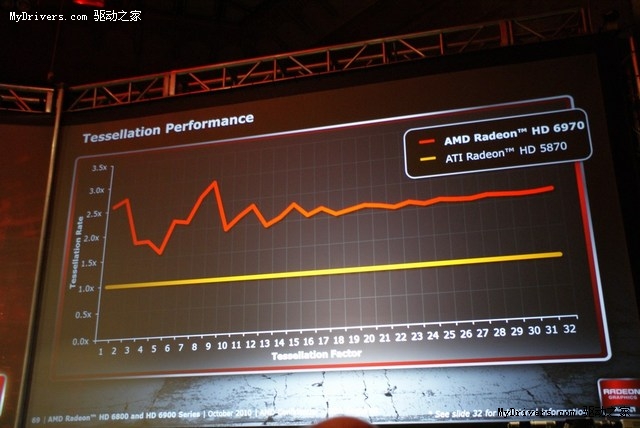
以及两个第八代曲面细分单元(Barts Radeon HD 6800是第七代),支持更高曲面细分等级的片外缓冲以提高性能,相比Radeon HD 5870提升最多三倍。

曲面细分技术因为厂商的宣传而成为DX11的热点,AMD此番更是将其进化到第八代,并宣称自己的做法才是正确的,包括专注于最有效的曲面细分使用模型、自适应曲面细分等等,可以做到性能与画质的平衡。

在不同曲面细分因数下,Radeon HD 6970的曲面细分性能可以达到Radeon HD 5870的1.5-3.0倍。
渲染器后端的改进包括写入操作合并、16位整数(unorm/snorm)操作速度提升2倍、32位浮点(单/双精度)操作速度提升2-4倍。

GPU计算增强包括异步分配(多个计算内核同步执行/每个内核拥有自己的命令队列和受保护虚拟寻址域)、两个双向DMA引擎(加快系统内存读写速度)、着色器读取操作合并、LDS(本地数据共享)直接拾取、改进的流控制、更快的双精度操作(单精度的四分之一)。

增强质量抗锯齿(EQAA)是一种新的多重采样抗锯齿(MSAA),每像素最多16个采样点,色彩和采样点数量可以独立控制,而且能够自行配置采样模式和过滤器。
AMD宣称该技术能够在使用同样容量显存的基础上带来更好的画质,而且兼容自适应AA、超级采样抗锯齿(SSAA)、形态抗锯齿(MLAA)。

EQAA、MSAA采样点模式对比:

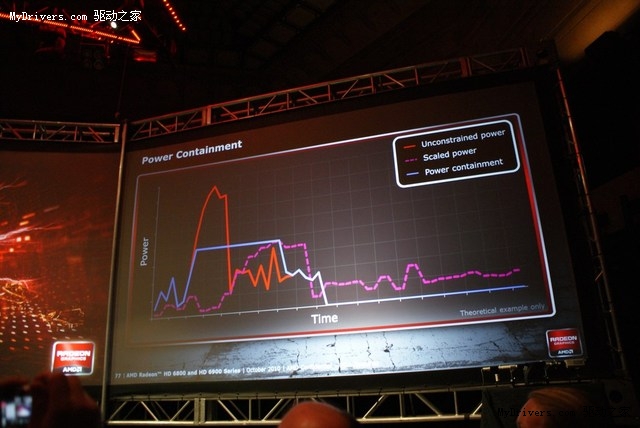
随着核心面积的增大,功耗控制也越发重要。Radeon HD 6900会集成一颗功耗控制处理器,每个时钟周期都会实时监控功耗并进行动态调整,而且可以直接工制GPU核心功耗,不再绕过频率、电压调整,此外也支持AMD OverDrive工具。

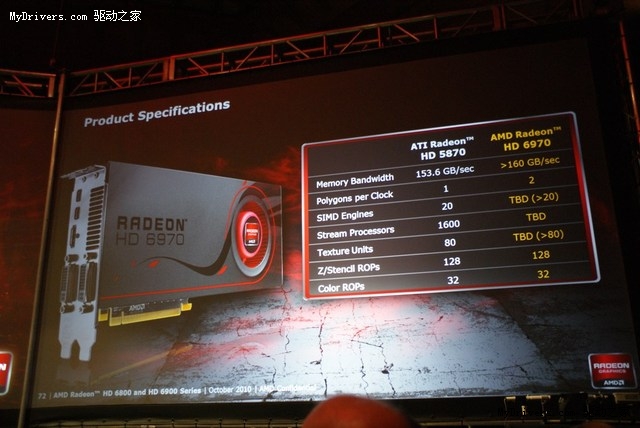
Radeon HD 6970的最终规格仍未明确公布。每时钟周期处理三角形数量为两个(Radeon HD 5870一个);Z/Stencil ROP单元、Color ROP单元分别仍是128个和32个;SIMD引擎、纹理单元只说分别大于20个和80个,猜测应该是30个和120个;显存带宽大于160GB/s,说明显存等效频率确实会超过5Gbps。