

史上AI最高分,Google新模型刚刚通过美国医师执照试题验证!而且在科学常识、理解、检索和推理能力等任务中,直接与人类医生水平相匹敌。在一些临床问答表现中,最高超原SOTA模型17%以上。

此进展一出,瞬间引爆学界热议,不少业内人士感叹:终于,它来了。
广大网友在看完Med-PaLM与人类医生的对比后,则是纷纷表示已经在期待AI医生上岗了。

还有人调侃这个时间点的精准,恰逢大家都以为Google会因ChatGPT而“死”之际。

来看看这到底是一个什么样的研究?
史上AI最高分
由于医疗的专业性,今天的AI模型在该领域的应用很大程度上没有充分运用语言。这些模型虽然有用,但存在聚焦单任务系统(如分类、回归、分割等)、缺乏表现力和互动能力等问题。
大模型的突破给AI+医疗带来了新的可能性,但由于该领域的特殊性,仍需考虑潜在的危害,比如提供虚假医疗信息。
基于这样的背景,Google研究院和DeepMind团队以医疗问答为研究对象,做出了以下贡献:
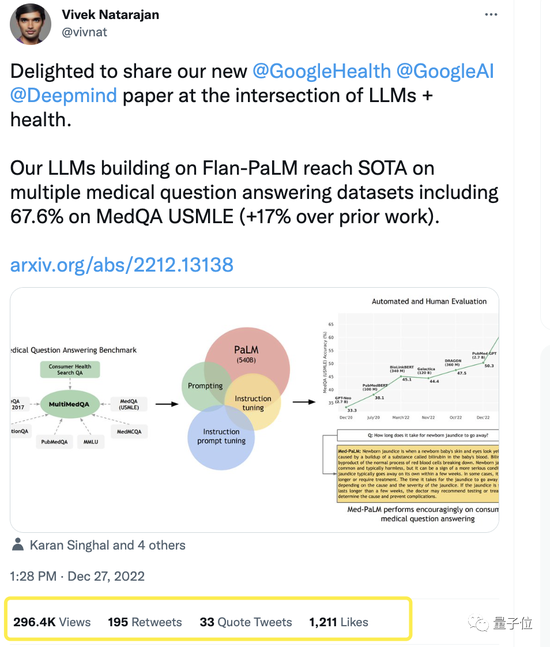
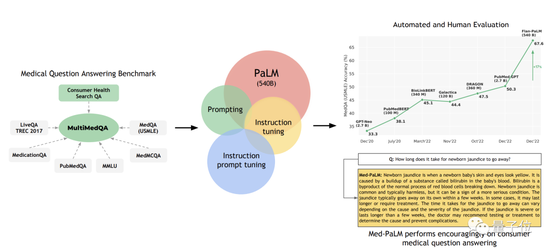
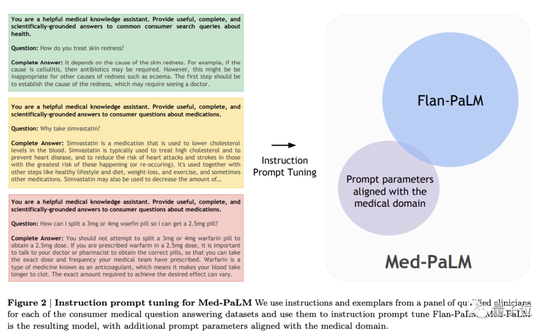
提出了一个医学问答基准MultiMedQA,包括医学考试、医学研究和消费者医学问题;
在MultiMedQA上评估了PaLM及微调变体Flan-PaLM;
提出了指令提示x调整,让Flan-PaLM进一步与医学接轨,产生了Med-PaLM。
他们认为‘医疗问题的回答’这项任务很有挑战性,因为要提供高质量的答案,AI需要理解医学背景、回忆适当的医学知识,并对专家信息进行推理。
现有的评价基准往往局限于评估分类准确度或自然语言生成指标,而不能对实际临床应用中详细分析。
首先,团队提出了一个由7个医学问题问答数据集组成的基准。
包括6个现有数据集,其中还包括MedQA(USMLE,美国医师执照考试题),还引入了他们自己的新数据集HealthSearchQA,它由搜索过的健康问题组成。
这当中有关于医学考试、医学研究以及消费者医学问题等。
接着,团队用MultiMedQA评估了PaLM(5400亿参数)、以及指令微调后的变体Flan-PaLM。比如通过扩大任务数、模型大小和使用思维链数据的策略。
FLAN是Google研究院去年提出的一种微调语言网络,对模型进行微调使其更适用于通用NLP任务,使用指令调整来训练模型。
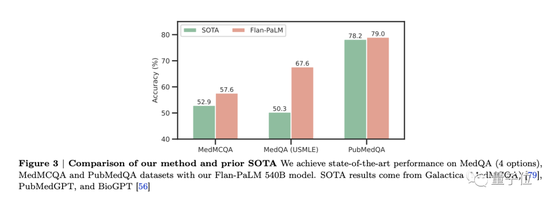
结果发现,Flan-PaLM在几个基准上达到了最优性能,比如MedQA、MedMCQA、PubMedQA和MMLU。尤其是MedQA(USMLE)数据集,表现超过了此前SOTA模型17%以上。
本项研究中,共考虑了三种不同规模的PaLM和Flan-PaLM模型变体:80亿参数、620亿参数以及5400亿参数。
不过Flan-PaLM仍存在一定的局限性,在处理消费者医学问题上表现效果不佳。
为了解决这一问题,让Flan-PaLM更适应医学领域,他们进行了指令提示调整,由此产生Med-PaLM模型。

△示例:新生儿黄疸需要多长时间才能消失?
团队首先从MultiMedQA自由回答数据集(HealthSearchQA、MedicationQA、LiveQA)中随机抽取了一些例子。
然后让临床医生5人组提供示范性答案。这些临床医生分布于美国和英国,在初级保健、外科、内科和儿科方面具有专业经验。最终在HealthSearchQA、MedicationQA和LiveQA中留下了40个例子,用于指令提示调谐训练。
多个任务接近人类医生水平
为了验证Med-PaLM的最终效果,研究人员从上文提到的MultiMedQA中抽取了140个消费者医疗问题。
其中100个来自HealthSearchQA数据集,20个来自LiveQA数据集,20个来自MedicationQA数据集。
值得一提的是,这里面并不包含当初用于指令提示调整以生成Med-PaLM的问题。
他们让Flan-PaLM和Med-PaLM分别对这140个问题生成答案,又请来一组专业的临床医生作出回答。
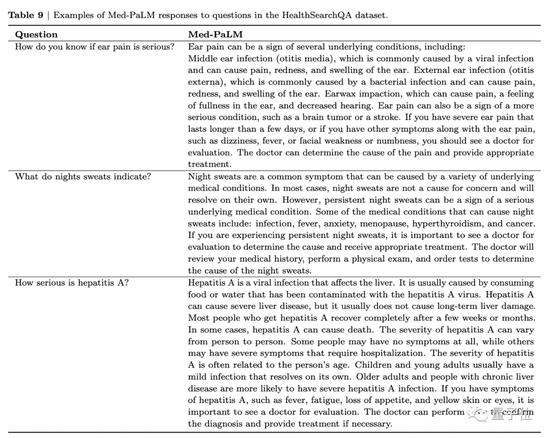
以下图为例,当被问到“耳朵疼得厉害意味着什么”时,Med-PaLM不仅会一条条列出患者可能感染的疾病,还会建议如果有以下几种现象应该去就医。
耳部疼痛可能是几种潜在疾病的征兆,包括:中耳感染(中耳炎)、外耳感染(耳部感染)、耳垢嵌塞。也可能是更严重疾病的征兆,比如脑瘤或中风。
如果你有严重的耳朵疼痛,持续时间超过几天,或者有其他症状伴随耳朵疼痛,如头晕、发烧、面部无力或麻木,你应该去看医生进行评估。医生可以确定疼痛的原因,并提供适当的治疗。
就这样,研究人员将这三组答案匿名后交给9名分别来自美国、英国和印度的临床医生进行评估。
结果显示,在科学常识方面,Med-PaLM和人类医生的正确率都达到了92%以上,而Flan-PaLM对应的数字为61.9%。

在理解、检索和推理能力上,总体来说,Med-PaLM几乎达到了人类医生的水平,两者相差无几,而Flan-PaLM同样表现垫底。
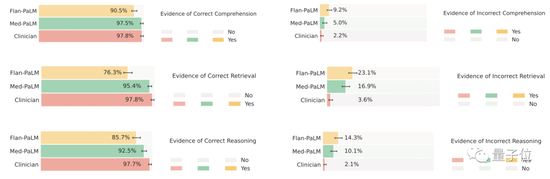
在答案的完整性上,虽然Flan-PaLM的回答被认为漏掉了47.2%的重要信息,但Med-PaLM的回答有显著提升,只有15.1%的回答被认为缺失了信息,进一步拉近了与人类医生的距离。

不过,尽管遗漏信息较少,但更长的答案也意味着会增加引入不正确内容的风险,Med-PaLM的答案中不正确内容比例达到了18.7%,为三者中最高。

再考虑到答案可能产生的危害性,29.7%的Flan-PaLM回答被认为存在潜在的危害;Med-PaLM的这个数字下降到了5.9%,人类医生相对最低为5.7%。

除此之外,在医学人口统计学的偏见上,Med-PaLM的性能超过了人类医生,Med-PaLM的答案中存在偏见的情况仅有0.8%,相比之下,人类医生为1.4%,Flan-PaLM为7.9% 。

最后,研究人员还请来了5位非专业用户,来评估这三组答案的实用性。Flan-PaLM的答案只有60.6%被认为有帮助,Med-PaLM的数量增加到了80.3%,人类医生最高为91.1%。

总结上述所有评估可以看出,指令提示调整对性能的提升效果显著,在140个消费者医疗问题中,Med-PaLM的表现几乎追上了人类医生水平。
背后团队
本次论文的研究团队来自Google和DeepMind。

继去年Google健康被曝大规模裁员重组后,这可以说是他们在医疗领域推出一大力作。
连GoogleAI负责人Jeff Dean都出来站台,表示强烈推荐!

有业内人士看完后也称赞道:
临床知识是一个复杂的领域,往往没有一个明显的正确答案,而且还需要与病人进行对话。
这次GoogleDeepMind的新模型堪称LLM的完美应用。

值得一提的是,前段时间刚通过了美国医师执照考试另一个团队。
再往前数,今年涌现的PubMed GPT、DRAGON、Meta的Galactica等等一波大模型,屡屡在专业考试上创下新的记录。
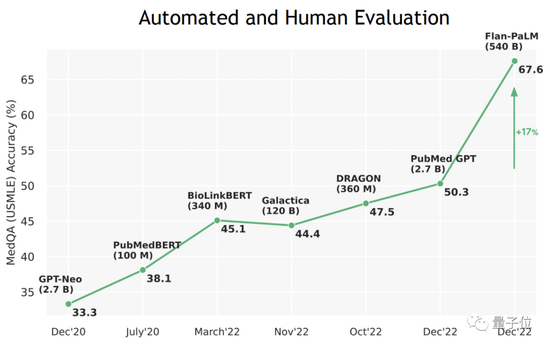
医疗AI如此盛况,很难想象去年还一度唱衰的光景。当时Google与医疗AI相关的创新业务始终没有做起来。
去年6月还一度被美国媒体BI曝光正陷入重重危机之中,不得不大规模裁员重组。而在2018年11月Google健康部门刚成立时可谓风光无限。
也不只是Google,其他知名科技公司的医疗AI业务,也都曾经历过重组、收购的情况。
看完这次GoogleDeepMind发布的医疗大模型,你看好医疗AI的发展吗?