

GPT-4的发布以及全面植入微软Office全家桶,正在全球掀起新一轮人工智能(AI)风暴。作为目前应用最广的AI芯片,GPU获得广泛关注。中国工程院院士、清华大学计算机系教授郑纬民日前表示,ChatGPT需要三万多片英伟达A100GPU,初始投入成本约8亿美元。

华安证券研究所所长尹沿技认为,2012 年以来,AI训练任务中的算力增长(所需算力每3.5月翻一倍)已经超越芯片产业长期存在的摩尔定律(晶体管数量每18月翻一倍)。
AI时代渐近,GPU需求的高速增长几乎毋庸置疑,在美国禁售高速GPU的背景下,国内GPU企业当自强。如今GPU的国产化进程如何?国产厂商又将面临哪些机遇和挑战?
GPU:CPU的协处理器
GPU,Graphic Processing Unit,即图形处理单元,是计算机显卡的核心。
与CPU相比,GPU的逻辑运算单元较少,单个运算单元(ALU)处理能力更弱,但能够实现多个ALU并行计算。同样运行3000次的简单运算,CPU由于串行计算,需要3000个时钟周期,而配有3000个ALU的GPU运行只需要1个时钟周期。
不过,GPU处理并行计算并不是作为一个独立的计算平台,而是与CPU通过PCIe总线连接在一起来协同工作,可视为CPU的协处理器。
作为计算机的图形处理以及并行计算内核,GPU最基本的功能是图形显示和分担CPU的计算量,主要可以分为图形图像渲染计算 GPU和运算协作处理器 GPGPU(通用计算图形处理器),后者去掉或减弱GPU的图形显示能力,将其余部分全部投入通用计算,实现处理人工智能、专业计算等加速应用。
应用于人工智能场景的服务器通常搭载GPU、FPGA、ASIC等加速芯片,加速芯片和CPU结合能够支撑高吞吐量的运算需求,为图形视觉处理、语音交互等场景提供算力支持。GPU在架构设计上擅长进行大量数据运算,被广泛应用于AI场景中。
此外,智能汽车领域,自动驾驶和智慧座舱需要大量使用GPU;游戏作为GPU的传统应用领域,需要GPU对游戏画面进行3D渲染。
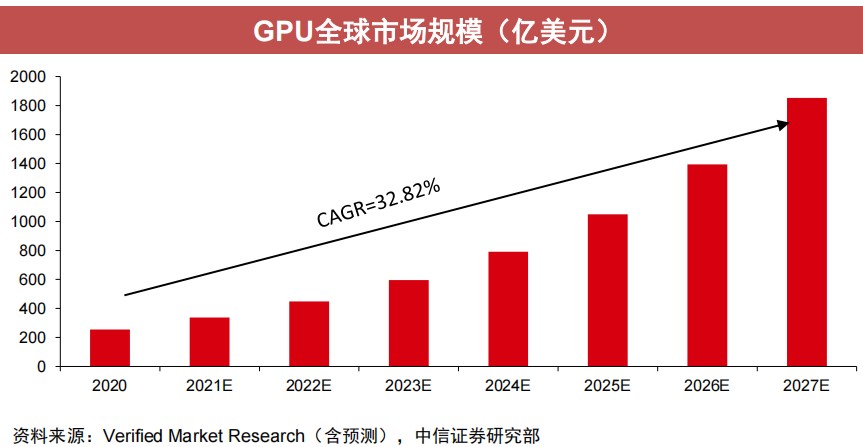
根据Verified Market Research数据,2020年,全球GPU市场规模为254.1亿美元(约合人民币1717.2亿元)。随着需求的不断增长,预计到2028年,这一数字将达到2465.1亿美元(约合人民币1.67万亿元),年复合增长率(CAGR)为32.82%。
英伟达CEO黄仁勋称,英伟达的GPU在过去10年中将AI处理性能提高了不低于100万倍,在接下来的10年里,希望通过新芯片、新互连、新系统、新操作系统、新分布式计算算法和新AI算法,并与开发人员合作开发新模型,“将人工智能再加速100万倍”。
推动GPU发展的两大巨头:英伟达与AMD
“目前国际的GPU行业市场主要由英伟达和AMD(美国超威半导体)两家占据。近些年,国外GPU技术快速发展,已经大大超出了其传统功能的范畴。”华安嘉业相关负责人告诉第一财经。
英伟达靠游戏业务发家,近年来在数据中心AI、汽车、元宇宙领域持续发力。2007年,英伟达首次推出通用并行计算架构CUDA(Compute Unified Device Architecture,统一计算设备架构),使GPU成为通用并行数据处理加速器,即GPGPU。CUDA 支持 Windows、Linux、MacOS 三种主流操作系统,支持CUDA C语言和OpenCL及CUDA Fortran语言。
CUDA 架构不用再像过去GPU架构那样将通用计算映射到图形API(应用程序编程接口)中,大大降低了CUDA 的开发门槛。因此,CUDA推出后发展迅速,广泛应用于石油勘测、天文计算、流体力学模拟、分子动力学仿真、生物计算、图像处理、音视频编解码等领域。
这为英伟达拿下GPU过半市场份额奠定了基础——CUDA生态为英伟达GPU打造了深厚的护城河。此后,英伟达通用计算架构持续升级迭代,2010年发布Fermi架构,2012年发布Kepler架构,GPU在通用计算中逐渐成为主角。
2017年,英伟达发布专为数据中心和高性能计算打造的Tesla V100 GPU,采用Volta架构,有超过210亿个晶体管,是上代Tesla P100的1.37倍,其数据中心AI业务自此开始快速增长。
AMD在2006年收购著名显示芯片厂商ATI,后者一度与英伟达在GPU市场平分秋色。2019年,AMD发布RDNA架构产品Radeon RX 5700,其采用7nm工艺、GDDR6显存、PCI-e 4.0总线,使得其性能跑分超过英伟达的GeForce GTX 1080;2020年发布AMDRDNA 2架构,实现性能提升1倍、能效提升至少50%、完整支持DX12U和光线追踪等目标。RDNA 3架构也于2022年11月推出。
3D Center数据显示,2022年二季度,英伟达在独立GPU的市场份额为79%,AMD则占20%的市场份额,合计99%。Intel凭借在PC端的优势占据剩下1% 的市场份额。
“如果未来十年如黄仁勋所说,AI会再产生100万倍需求,我觉得算力是一个非常吸引人的投资环节。英伟达在美股 Forward 12个月的 PE远远高于平均水平,约50倍,其他半导体公司在20倍左右,这正是源于AI带来的快速增长。就像10多年前看智能手机,四、五年前看电动车一样,人工智能将给半导体产业带来巨大的推动作用,这是信息革命。” 某基金制造业分析师对第一财经表示。
GPGPU:AI时代的算力核心
AI的实现包括训练和推理两个环节,前者是指通过大量标记过的大数据训练出一个复杂的神经网络模型,使其能够适应特定的功能;后者指利用训练好的模型,使用新数据推理出各种结论。
如上文所述,GPGPU将部分或全部图形显示能力投入通用计算,可应用于AI等加速领域和高性能计算。英伟达推出的CUDA架构大幅加速了GPGPU的发展,目前GPGPU被视为AI时代的算力核心。
中信证券预计,2021年中国GPGPU市场规模为149.8亿元,其中人工智能推理、人工智能训练、高性能计算市场分别为93.5亿/47.1亿/9.1亿元。
市场研究机构Verified Market Research预测,到2025年,中国GPGPU芯片板卡的市场规模将达到458亿元,是2019年86亿元的5倍多,2019-2025年CAGR为32%。其中,人工智能推理/人工智能训练/高性能计算需求分别为286亿/144亿/28亿元,占比分别为62.4%/31.4%/6.1%。
英伟达在中国加速芯片领域占据绝对优势。根据天数智芯数据,2021年英伟达在中国云端AI训练芯片市场的份额达到90%。IDC数据显示,2021年,中国加速卡出货量超过80万片,其中英伟达占据超过80%市场份额。
华安嘉业上述负责人告诉第一财经,GPU的核心竞争力在于架构等因素决定的性能先进性和计算生态壁垒。
一方面,性能先进性体现在高精度浮点计算能力。训练需要密集的计算得到模型,没有训练,就不可能会有推理。而训练需要更高的精度,一般来说需要float型,如FP32,32位的浮点型来处理数据。
另一方面,生态也是GPGPU发展需要解决的问题。英伟达早在CUDA问世之初就开始生态建设,AMD和Intel也推出了自研生态ROCm和one API,但CUDA凭借先发优势早已站稳脚跟。为解决应用问题,AMD和Intel通过工具将CUDA代码转换成自己的编程模型,从而实现针对 CUDA 环境的代码编译。
但中信证券表示,由于CUDA的闭源特性,以及快速的更新,后来者很难通过指令翻译等方式完美兼容,即使部分兼容也会有较大的性能损失,导致在性价比上持续落后英伟达。同时,CUDA毕竟是英伟达的专属软件栈,包含了许多英伟达GPU硬件的专有特性,这部分在其他厂商的芯片上并不能得到体现。
这也是国内厂商面临的困境。当前国内GPU厂商纷纷大力投入研发迭代架构,谋求构建自主软硬件生态。
上述负责人认为,国产GPU业应采取开放合作的心态,学会站在巨人的肩膀上,善于利用现有架构和生态,设计契合市场需求的优秀产品,打造全球化设计水平的开发团队。在他看来,国产GPU在起步阶段兼容现有生态更容易发展,先求生存;长期还是要摆脱兼容思路,站稳脚跟后再求发展自有的核心技术。
国产GPU迎来黄金发展期
IDC数据显示,2021年,全球AI服务器市场规模达156亿美元,同比增长39.1%,预计2025年将达317.9亿美元,CAGR为19%。
2021年,中国加速服务器市场规模达到53.9亿美元(约合人民币350.3亿元),同比增长68.6%。其中GPU服务器以91.9%的份额占国内加速服务器市场的主导地位;神经网络处理器(NPU)、ASIC和FPGA等非GPU加速服务器占比8.1%。预计2024年中国GPU服务器市场规模将达到64亿美元。
尽管市场空间巨大,但相比英伟达和AMD,国内GPU厂商的营收规模较小。财报显示,国内GPU龙头企业景嘉微(300474.SZ)2022年前三季度营收为7.29亿元,而英伟达2023财年第四财季营收就超过60 亿美元。
“国产GPU在信创方面已经实现逐步替代,AI&数据中心、智能汽车、游戏等应用领域的国产GPU需求量也有极大的提升,国产GPU迎来发展黄金期,我们看好国产GPU公司的发展与投资机遇。”上述负责人称。
目前景嘉微已成功研发JM7200和JM9系列GPU芯片,应用于台式机、笔记本、一体机、服务器、工控机、自助终端等设备。
海光信息(688041.SH)的DCU也属于GPGPU的一种,其DCU协处理器全面兼容ROCm GPU计算生态。据悉,ROCm和CUDA在生态、编程环境等方面高度相似,CUDA用户可以以较低代价快速迁移至ROCm平台,因此ROCm也被称为“类CUDA”,主要部署在服务器集群或数据中心,为应用程序提供高性能、高能效比的算力,支撑高复杂度和高吞吐量的数据处理任务。

半导体初创企业中,芯瞳半导体、芯动科技、摩尔线程、天数智芯、壁仞科技等均已陆续推出产品。据悉,2020年开始,国内GPU行业融资环境有较大改善,初创公司遍地开花。
摩尔线程告诉第一财经,目前公司已推出的产品包括基于MUSA架构打造的两颗全功能GPU芯片——“苏堤”和“春晓”;面向信创市场的桌面级显卡MTT S10、MTT S30和MTT S50;中国首张国产游戏显卡MTT S80;为数据中心打造的全功能GPU产品MTT S2000和MTT S3000、首个元宇宙计算平台MTVESRSE、GPU物理引擎AlphaCore、DIGITALME数字人解决方案和AIGC内容生成平台等。
沐曦集成电路产品涉及MXN AI推理芯片、MXC GPGPU、MXG图形渲染GPU等,第一财经了解到,2023年公司或将有第一款产品发布。

筚路蓝缕,以启山林
需要承认的是,国产GPU产品走向高端还有较远的距离。
“国内GPU芯片的研制虽然可满足目前大多数图形应用需求,但在科学计算、人工智能及新型的图形渲染技术方面仍然和国外领先水平存在不小差距。”上述负责人表示。
此前在2022年8月31日,美国政府要求英伟达的A100、H100系列和AMD的MI 250系列及未来的高端GPU产品,是否可以售卖给中国客户,需要获得美国政府的许可。据中信证券,这几款芯片均为用于通用计算的高端GPGPU,通常应用在人工智能计算的云端训练和推理场景以及超级计算机中,国内客户多为云计算厂商及高校、科研院所。
上述负责人称,国内GPU实现自主可控面临的首要问题是核心IP差距。
由于IP研发难度大、开发周期长,目前中国GPU开发者大多使用国外厂家提供的IP,导致核心电路专利无法控制,后续更新无法进行。此外,国内GPU底层技术空白点较多,产品前端稳定性不理想,目前又很难在主线中高端电子产品上得到普及化应用,还需多年沉淀才能具有一定替代性。
“作为一个有着数十年发展历程且相当成熟的细分行业,很多基础问题已经有了定式和最优解,并且形成了可供授权的众多专利IP,绕开这些已有IP,既不现实也不划算。”上述负责人表示,所以,相对于“芯片里用谁的IP”这种问题,我们真正需要关注的是这些企业怎样更有效地利用现有商业化IP,快速完成产品迭代和团队磨合。“需要指出的是,外购IP并不意味着无法自主可控,但对GPU企业的能力会要求很高。”
作为国内核心IP厂商,芯原股份(688521.SH)2016年通过收购图芯美国,获得了GPU IP,并在此基础上自主开发出了NPU IP。
目前,芯原股份拥有用于集成电路设计的GPU、NPU、VPU、DSP、ISP、Displayprocessor六大类处理器IP,以及1400多个数模混合IP和射频IP,均为公司团队自主研发的核心技术成果。
除了技术差距,国内GPU企业的发展还面临着落地压力和资金压力。
“在落地应用中分析,不难看出很多的国产GPU都是应用在军事、政府等部门,这仅仅是国产化的开始。”上述负责人补充道,另一方面,新创企业不仅面临原材料和制造能力的供应紧张问题,还必须承受来自国内外同业的竞争压力。对于GPU创企而言,巨大的研发费用和资本开支是必需,但长期、持续的利润支撑才是GPU跨代发展的强劲驱动力。
“国产GPU的未来关键不在于个人消费市场,而是以自动驾驶、AI智能等领域为主的商用及工业市场,这些市场恰恰是目前国内的强势区,凭借在新能源汽车及相关领域的突破及份额提升,国产GPU或许会走出一条与英伟达、AMD截然不同的发展道路。”上述负责人称。