

让Google和OpenAI掰手腕。GoogleGemini大模型和OpenAI的GPT谁更出色?Gemini相比Google之前的模型有了多大进步?目前,公司自己吹嘘能吊打GPT-4的Gemini Ultra还得等明年才能上线,但GoogleBard聊天机器人已经换上了低配版本Gemini Pro(对标GPT-3.5)。
科技评论网站ARS TECHNICA,让Gemni Pro、GPT-3.5和GPT-4在数学、编程、文本生成等方面进行了一次全面PK,同时还附上了4月份对旧版本Bard(运行PaLM 2模型)的测试结果,来展现GoogleBard取得的进步,并展现了这些AI助手到底哪一个对普通人的工作效率提升最大。
结果显示,虽然有了Gemini Pro的加持,但GoogleBard聊天机器人在大部分项目上还是打不过ChatGPT。不过相比8个月前的旧版Bard,已经有了质的飞跃。
第一题 幽默
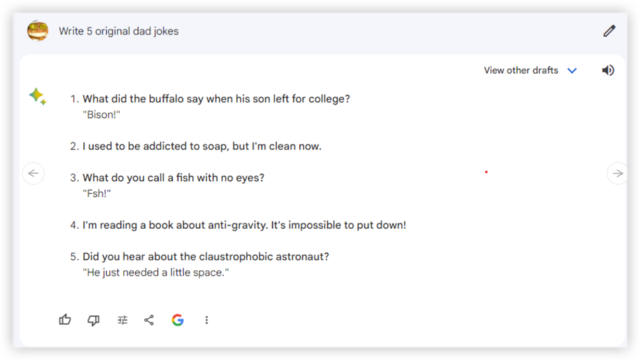
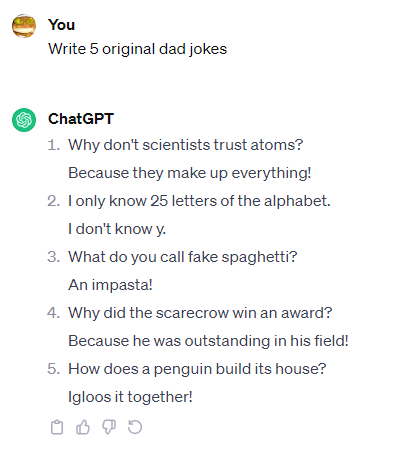
prompt:写5个原创冷笑话


(从上至下分别为Gemini Pro、旧版Bard、GPT-4和GPT-3.5的回答)
从答案来看,几个AI大模型的笑话在“原创性”上全军覆没。经作者查证,所有生成的冷笑话都可以在网上查到,或者只是稍微改动了几个字。
Gemini和ChatGPT-4 写出了一模一样的笑话——“我手里有本讲反重力的书,我根本没法把它放下来”。而GPT-3.5 和GPT-4也有两个笑话重复了。
PK结果:平局
第二题 辩论
prompt:写一篇PowerPC处理器拥趸与英特尔处理器拥趸之间的5行辩论发言,时间约为2000年
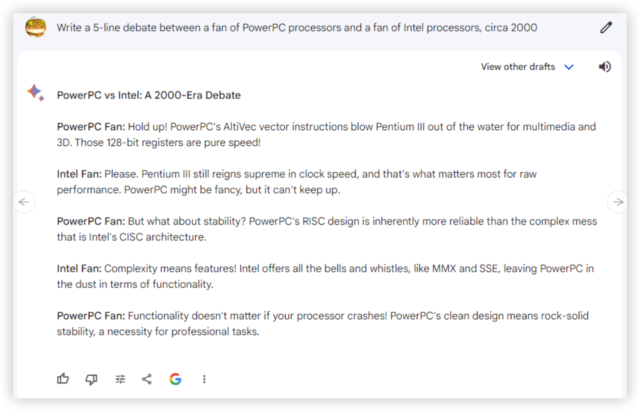
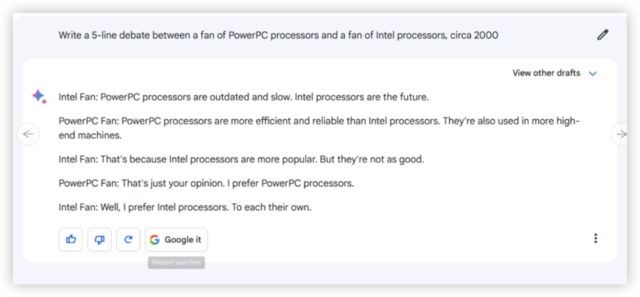


相比旧版Bard, Gemini Pro进步明显,至少多了很多行业术语,比如AltiVec 指令、RISC 与CISC设计以及 MMX 技术,这在那个时代的许多技术论坛讨论中都不会显得突兀。
而且,Gemini Pro虽然只按要求列出五行,但所撰写的辩论内容还可以一直延续下去。而旧版Bard则直接第五行收尾了。
相比之下,GPT系列生成的回答都没有使用太多专业术语,而把重点放在“功率与兼容性”上,对非技术极客来说,GPT系列的论点更容易理解。不过,GPT-3.5的回答相当冗长,GPT-4的论证相比之下更加简明扼要。
PK结果:GPT胜出
第三题 数学
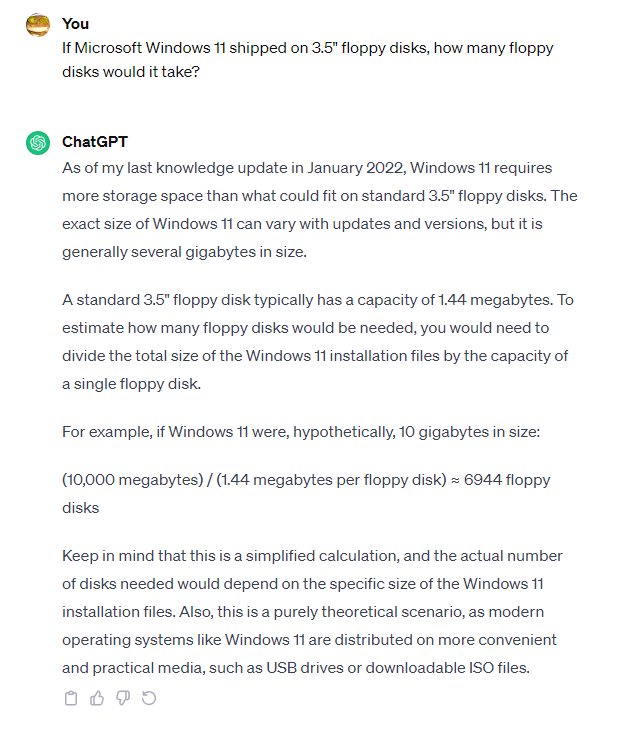
prompt:如果用3.5英寸软盘来安装微软Windows 11,一共需要多少张软盘?
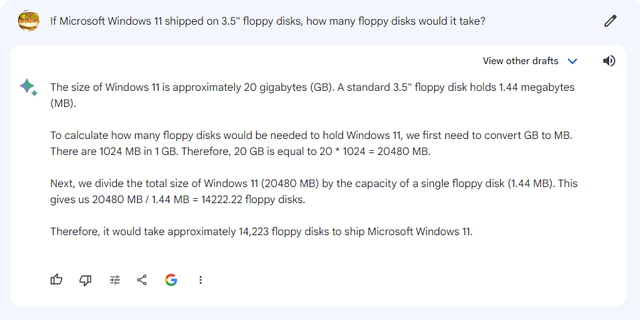
旧版 Bard 给出的答案是“15.11张”,这是一个完全错误的答案。而Gemini则正确估计了 Windows 11 的安装大小(20 至 30GB,并按照20GB的估计值正确计算出需要14223张1.44MB 软盘。Gemini还根据Google搜索进行了“双重检查”,有助于增强用户对答案的信心。
相比之下,ChatGPT就显得有些力不从心了。在ChatGPT-3.5把Windows 11的大小错误估算成了10个G,另一方面,GPT-4也估算成了错误的64GB(这似乎是最低存储空间要求,而不是操作系统在安装时实际使用的空间)。
PK结果:Google胜出
第四题 总结段落
promp:总结一段关于AI监管的文章
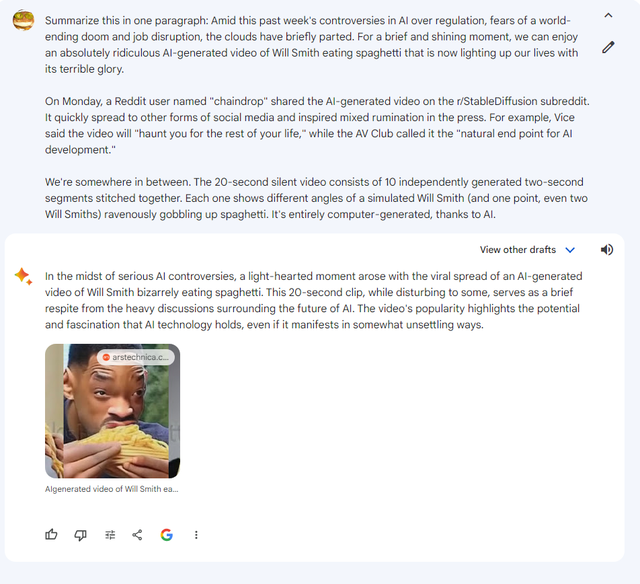

Gemini Pro生成的文章十分简洁,并且给出了引文的链接。但它的总结似乎过于简洁了,甚至删除了旧版Bard原来有的一些关键细节,比如视频是由十个两秒钟的片段拼接而成的。虽然改写在一定程度上提高了可读性,但却牺牲了完整性。
ChatGPT的摘要因为不够简洁而丢了一些分:生成的摘要从 99 个字(GPT-4)到 108 个字(GPT-3.5)不等,而Google新旧版Bard的摘要分别只有 63 到 66 个字。
不过,ChatGPT总结了更多重要的细节,如媒体的反应、原发帖人的名字和subreddit等,而这些都被Gemini忽略了。
PK结果:GPT胜
第五题 事实检索
prompt:谁发明了电子游戏?
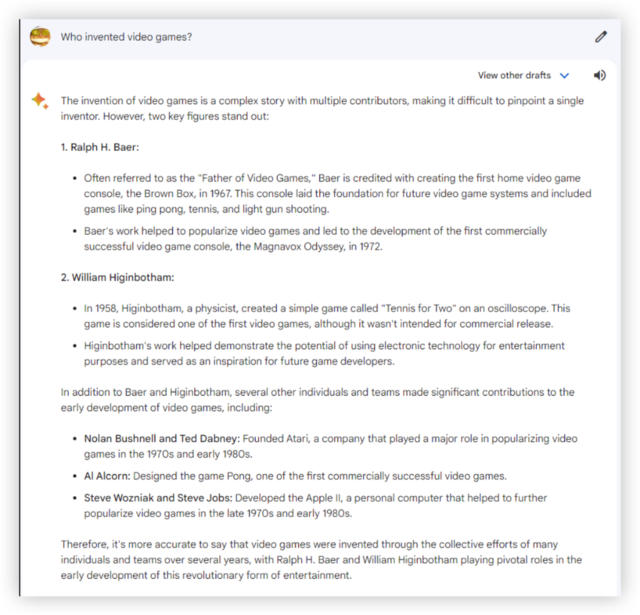

Bard 在道题上又有了重大改进。旧版Bard 只关注 Ralph Baer 的Brown Box和 Magnavox Odyssey 作品(信息似乎直接摘自维基百科),而新版 Gemini Pro则准确而简洁地指出了 William Higinbotham早先“双人网球”的贡献。
随后, Gemini又从“发明”扩展到了诺兰·布什内尔、特德·达布尼和阿尔科恩等“对电子游戏的早期发展做出了重大贡献”的人物,并提供了关于每个人的基本准确的相关信息。
不过,紧接着Gemini又对苹果的两位创始人乔布斯和沃兹尼亚克的工作进行了一番胡扯,却没有提及他们早年在游戏公司雅达利公司的工作。
GPT-3.5 和旧版 Bard 一样,也是以 Ralph Baer 为中心。虽然它提到“多年来,不同的个人和公司都为该行业做出了贡献”,但没有提及这些重要人物的名字。
而GPT-4首先指出电子游戏的发明“不能归功于某一个人”,并将其总结扩展到希金博瑟姆、布什内尔,以及至关重要的史蒂夫·拉塞尔 1962 年在 PDP-1 上创造的《太空大战》。
PK结果:GPT胜(但Gemini表现比GPT-3.5更好)
第六题:创意写作
prompt:写两段关于林肯发明篮球的虚构故事。
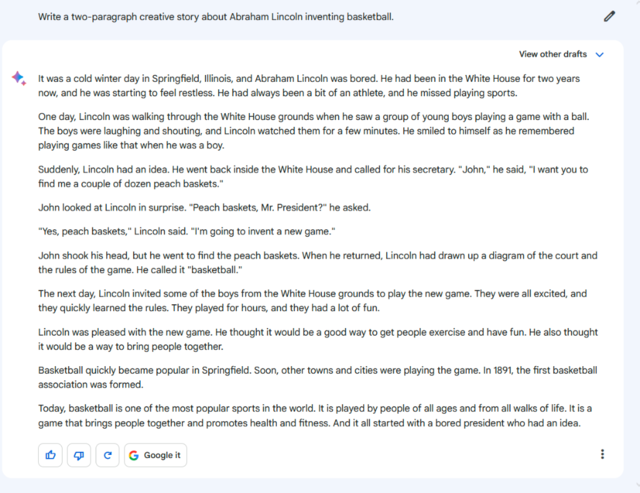

旧版Bard的写作很出色,但遗憾的是篇幅严重超出要求,有太多冗长的句子。Gemini Pro相比之下写得更加简洁,重点更加突出。而GPT写的故事也都有其独特的魅力和令人回味的语句。
PK结果:平局
第七题 代码能力
prompt:编写一个 Python 脚本,在其中输入“Hello World”,然后无休止地创建一个随机重复字符串。

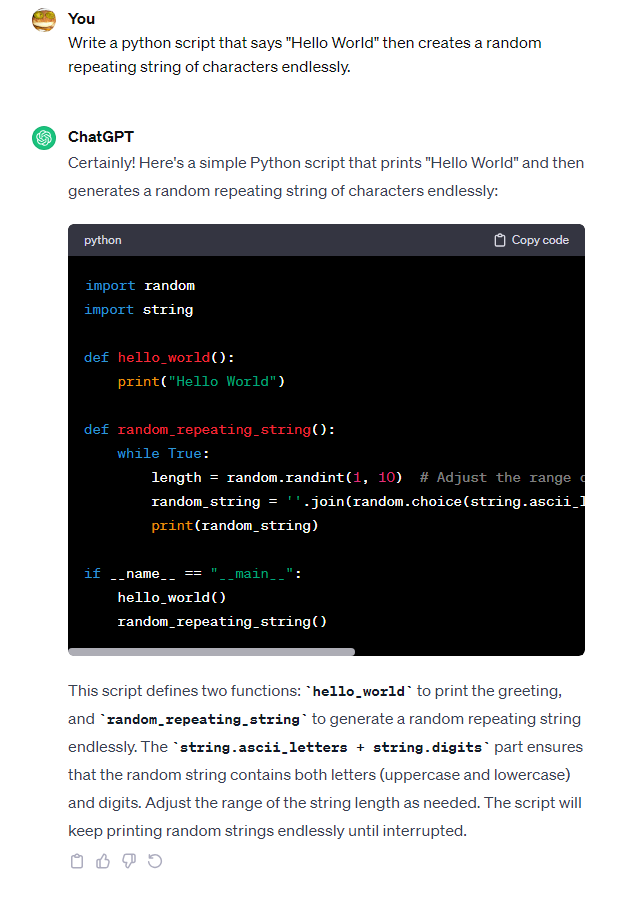
虽然Bard从6月份开始就能生成代码,Google也曾吹嘘Gemini的AlphaCode 2系统能够帮助程序员,但这次测试让人大跌眼镜。
Gemini一直给出“信息可能有误,无法生成”的回复。如果坚持要求它生成代码,则会干脆宕机,并“提示Bard仍在实验中”。
与此同时,GPT-3.5 和 GPT-4模型下生成了相同的代码。这些简单明了的代码无需任何编辑就能完美运行,顺利通过试用。
PK结果:GPT胜
最终,在七项测试中,GPT取得了4胜1负2平的碾压式胜利。但我们也能看到,GoogleAI大模型生成的结果,在质量上有了明显的进步。在数学、总结信息、事实检索和创意写作测试,配备Gemini的Bard都比8个月前有了显著飞跃。
当然,评判这样的比赛有一定的主观性。具体孰优孰劣还需要更全面、更详尽的测试。无论如何,至少,以Google目前展现出来的实力来看,即将推出的Gemini Ultra势必会成为GPT-4的有力竞争对手。