
OpenAI超级对齐团队正在分崩离析。团队负责人OpenAI联合创始人、首席科学家伊尔亚·苏茨克维(Ilya Sutskever)与杨·莱克(Jan Leike),本周双双离职。北京时间周五晚间,杨·莱克在社交平台X上公开解释了他为什么离职。他写到原因跟对核心优先事项以及团队分配资源的分歧有关,他更关注安全性、一致性等问题;超级对齐团队过去几个月一直在“逆风航行”,在计算上很吃力,完成研究越来越困难;过去几年,安全文化和流程已经让位于更耀眼的产品。

这似乎是OpenAI高管第一次公开表示OpenAI将产品置于安全之上。
对此,OpenAI联合创始人、CEO萨姆·阿尔特曼(Sam Altman)发文回应:“我非常感激杨·莱克对OpenAI的对齐研究和安全文化做出了贡献,看到他离开,我感到非常难过。他说得对,我们还有很多事情要做;我们致力于这样做。在接下来的几天里,我会有一个更长的帖子。”
OpenAI去年7月组建了超级对齐团队,由杨·莱克和伊尔亚·苏茨克维领导,目标是在未来4年内解决控制超级智能AI的核心技术挑战。该团队承诺将获得该公司20%的计算资源,但其实际获得计算资源却受到阻碍。
几个月来,OpenAI一直在流失关注AI安全的员工。自去年11月至今,OpenAI至少有7名注重安全的成员辞职或被开除。
据《连线》证实,OpenAI超级对齐团队已经解散,余下成员要么辞职,要么将被纳入OpenAI的其他研究工作中。
杨·莱克公开离职原因:
团队逆风前行,拿计算资源很吃力
前OpenAI超级对齐团队联合负责人杨·莱克(Jan Leike)昨晚连发13条推文,公开了离职原因:
昨天是我作为OpenAI的对齐负责人、超级对齐负责人和执行官的最后一天。
在过去的3年里,这是一段疯狂的旅程。我的团队使用InstructGPT推出了第一个RLHF LLM,发布了第一个可扩展的LLM监督,率先实现了自动化可解释性和弱到强的泛化。更多令人兴奋的东西即将问世。
我爱我的团队。
我非常感谢和我一起工作的许多了不起的人,包括超级联盟团队内部和外部的人。
OpenAI拥有如此多非常聪明、善良和高效的人才。
离开这份工作是我做过的最艰难的事情之一,因为我们迫切需要弄清楚如何引导和控制比我们聪明得多的AI系统。
我加入是因为我认为OpenAI将是世界上做这项研究最好的地方。
然而,很长一段时间以来,我与OpenAI领导层对公司核心优先事项的看法一直不合,直到我们终于到了临界点。
我认为,我们应该把更多的带宽用于为下一代模型做好准备,包括安全性、监控、准备、对抗鲁棒性、(超级)一致性、保密性、社会影响和相关主题。
这些问题很难解决,我担心我们没有走在到达那里的轨道上。
过去几个月里,我的团队一直在逆风航行。有时我们在计算上很吃力,完成这项重要的研究变得越来越困难。
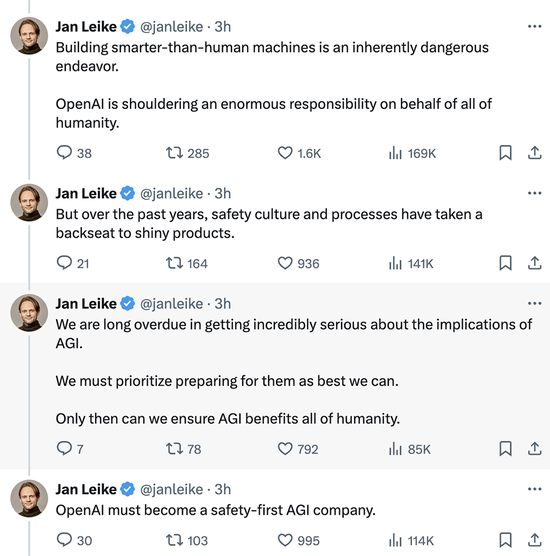
建造比人类更聪明的机器本身就是一项危险的尝试。
OpenAI代表着全人类肩负着巨大的责任。
但过去几年,安全文化和流程已经让位于耀眼的产品。
我们早就应该认真对待AGI的影响了。
我们必须尽可能优先做好准备。
只有这样,我们才能确保AGI造福全人类。
OpenAI必须成为一家安全第一的AGI公司。
对所有OpenAI员工,我想说:
学会感受AGI。
举止要庄重得体,为你们正在构建的东西。
我相信你们可以“传递”所需的文化变革。
我就指望你们了。
全世界都指望着你们。
: openai-heart:’

大量关心AI安全的员工离职,
苏茨克维半年没出现在OpenAI办公室
几个月来,OpenAI一直在流失那些关心AI安全的员工。
OpenAI超级对齐团队由OpenAI之前的校准部门的科学家和工程师以及来自公司其他机构的研究人员加入。他们将为内部和非OpenAI模型的安全性提供研究信息,并通过包括研究资助计划在内的倡议,向更广泛的AI行业征求并分享工作。
该团队负责开发管理和引导“超级智能”AI系统的方法。据OpenAI超级对齐团队的一位人士透露,该团队承诺将获得公司20%的计算资源,但对其中一小部分计算的请求经常被拒绝,阻碍了团队的工作。
一系列问题促使几名团队成员本周辞职。
OpenAI没有立即回复关于承诺和分配给该团队的资源的评论请求。
据消息人士透露,苏茨克维对超级对齐团队很有帮助,不仅贡献了研究,而且作为OpenAI内部其他部门的桥梁。他还将担任某种形式的大使,向OpenAI关键决策者展示团队工作的重要性。
苏茨克维与阿尔特曼之间的矛盾更是增加了他的受关注度。
去年11月,苏茨克维和OpenAI前董事会突然宣布开除阿尔特曼,理由是阿尔特曼对董事会成员“并不总是坦诚相待”。
在包括微软在内的OpenAI投资者和该公司许多员工的压力下,阿尔特曼最终复职,董事会大部分成员辞职换人。据报道,苏茨克维再也没有回去工作。
阿尔特曼复职后不久,苏茨克维曾发布一篇推文:‘上个月我学到了很多东西。其中一个教训是,“持续打击,直到士气提振”这句话的使用频率超出了它应有的范围。’

没过多久,这篇推文就被删除了。
此后在公开场合,苏茨克维和阿尔特曼继续保持着友谊的迹象,直到本周苏茨克维宣布离职时,阿尔特曼还将他称呼为“我亲爱的朋友”。
据外媒报道,自夺权事变落幕以来,苏茨克维已经有大约6个月没出现在OpenAI办公室了。他一直在远程领导超级对齐团队,负责确保未来的AGI与人类的目标保持一致,而非背道而驰。
这是个远大的抱负,但它与OpenAI的日常运营脱节。在阿尔特曼的领导下,该公司一直在探索将产品商业化。
对阿尔特曼的信任崩塌:
就像多米诺骨牌般一张张倒下
苏茨克维和莱克并不是唯二离开的人,自去年11月以来,OpenAI至少有5名注重安全的员工辞职或被开除。
关于阿尔特曼“不坦诚”的内因,业界众说纷纭,有一种猜测是OpenAI秘密取得了重大技术突破,认为苏茨克维选择离职是因为他看到了一些可怕的东西,比如一个可能摧毁人类的AI系统。
真正的答案,可能确实跟阿尔特曼有关。
据Vox报道,熟悉OpenAI的消息人士透露道,安全意识强的员工已经对阿尔特曼失去了信心。
一位不愿透露姓名的公司内部人士说:“这是一个信任一点一点崩塌的过程,就像多米诺骨牌一张一张倒下。”
没有多少员工愿意公开谈论此事。部分原因是OpenAI以让员工在离职时签署包含非贬损条款的离职协议而闻名。如果拒绝签署,员工就放弃了自己在公司的股权,这意味着可能会损失数百万美元。
但有一名前员工拒绝签署离职协议,以便可以自由批评公司。丹尼尔·科科塔伊洛(Daniel Kokotajlo)于2022年加入OpenAI,希望带领公司实现AI的安全部署,他一直在治理团队工作,直到上个月辞职。
“OpenAI正在训练越来越强大的AI系统,目标是最终全面超越人类智能。这可能是人类有史以来最好的事情,但如果我们不谨慎行事,也可能是最糟糕的事情,”科科塔伊洛说。
“我加入时满怀希望,希望OpenAI能够迎难而上,在他们越来越接近实现AGI的过程中表现得更加负责任。我们中的许多人逐渐意识到这不会发生,”他谈道。“我逐渐对OpenAI领导层及其负责任地处理AGI的能力失去了信心,所以我辞职了。”
尽管在公众面前展现出友情,但在苏茨克维试图赶走阿尔特曼后,人们对他们的友谊产生了怀疑。
阿尔特曼被解雇后的反应也展现了他的性格。他用掏空OpenAI来威胁董事会重新向他敞开大门。
前同事及员工纷纷透露说,阿尔特曼是一位口是心非的操纵者,例如他声称自己希望优先考虑安全,但实际行为却与此相矛盾。
此前阿尔特曼找沙特基金支持成立一家新AI芯片公司的消息,让有安全意识的员工感到震惊。如果阿尔特曼真的关心以最安全的方式构建和部署AI,为什么他似乎在疯狂积累尽可能多的芯片,而这只会加速技术的发展?
一位了解公司内部情况的消息人士称,对于员工来说,所有这些都导致他们逐渐“不再相信OpenAI说要做什么或者说重视某件事时,这些实际上是真的”。
杨·莱克是前DeepMind研究员,在OpenAI期间参与了ChatGPT、GPT-4和ChatGPT前身InstructGPT的开发。在苏茨克维宣布离职的几小时后,莱克发了个简短声明:“我辞职了。”

没有热情而友好地告别,没有表达对公司领导层的信任。
一些关注安全的OpenAI员工评论心碎的表情。
有安全意识的前员工也转发了莱克的推文,并附上了爱心表情符号。其中一位是利奥波德·阿森布伦纳(Leopold Aschenbrenner),他是苏茨克维的盟友,也是超级对齐团队成员,上个月被OpenAI解雇。媒体报道称,他和同团队的另一名研究员帕维尔·伊兹麦洛夫(Pavel Izmailov)因泄露信息而被解雇。但OpenAI并未提供任何泄密证据。
考虑到每个人加入OpenAI时都要签署的严格保密协议,如果阿尔特曼急于摆脱苏茨克维的盟友,那么对他来说,即使是最无害的信息,分享也是很容易被描绘成“泄密”。
就在阿申布伦纳和伊兹麦洛夫被迫离职的同一个月,安全研究员卡伦奥基夫也离开了公司。
两周前,另一位安全研究员威廉·桑德斯(William Saunders)在有效利他主义运动成员的在线聚会场所EA论坛上发表了一篇神秘的帖子,总结了他作为超级对齐团队成员在OpenAI所做的工作。他写道:“我于2024年2月15日从OpenAI辞职。”
对于为什么要发布这篇文章?桑德斯回答说“无可奉告”。评论者认为他可能受到协议约束。
还有一名从事AI政策和治理工作的OpenAI研究人员最近似乎也离开了该公司。库伦·奥吉菲(Cullen O‘Keefe)于4月辞任政策前沿研究负责人。
将所有这些信息结合起来,至少有7个人曾试图从内部推动OpenAI走向更安全的道路,但最终对其阿尔特曼失去了信心。
结语:超级对齐团队被解散后,
谁来确保OpenAI的AI安全?
在莱克和苏茨克维离开后,关于与更强大模型相关的风险的研究将由OpenAI的另一位联合创始人约翰·舒尔曼(John Schulman)领导。
而原来的OpenAI超级对齐团队,不再是一个专门的团队,而是一个松散的研究小组,分布在整个公司的各个部门。OpenAI的一位发言人将其描述为“更深入地整合(团队)”。
“成立超级对齐团队的重点在于,如果公司成功打造出AGI,实际上会出现不同类型的安全问题,”知情人士说,“这是对未来的一项专门投资。”
即使团队全力运作,这笔“专项投资”也只占OpenAI研究人员的一小部分,而且只承诺提供20%的计算能力。现在这些计算能力可能会被转移到其他OpenAI团队,目前还不清楚是否会将重点放在避免未来AI模型的灾难性风险上。
需明确的是,这并不意味着OpenAI现在发布的产品将毁灭人类。但接下来会发生什么呢?
“区分‘他们目前是否正在构建和部署不安全的AI系统?’与‘他们是否正在安全地构建和部署 AGI 或超级智能?’非常重要。”知情人士认为,第二个问题的答案是否定的。