
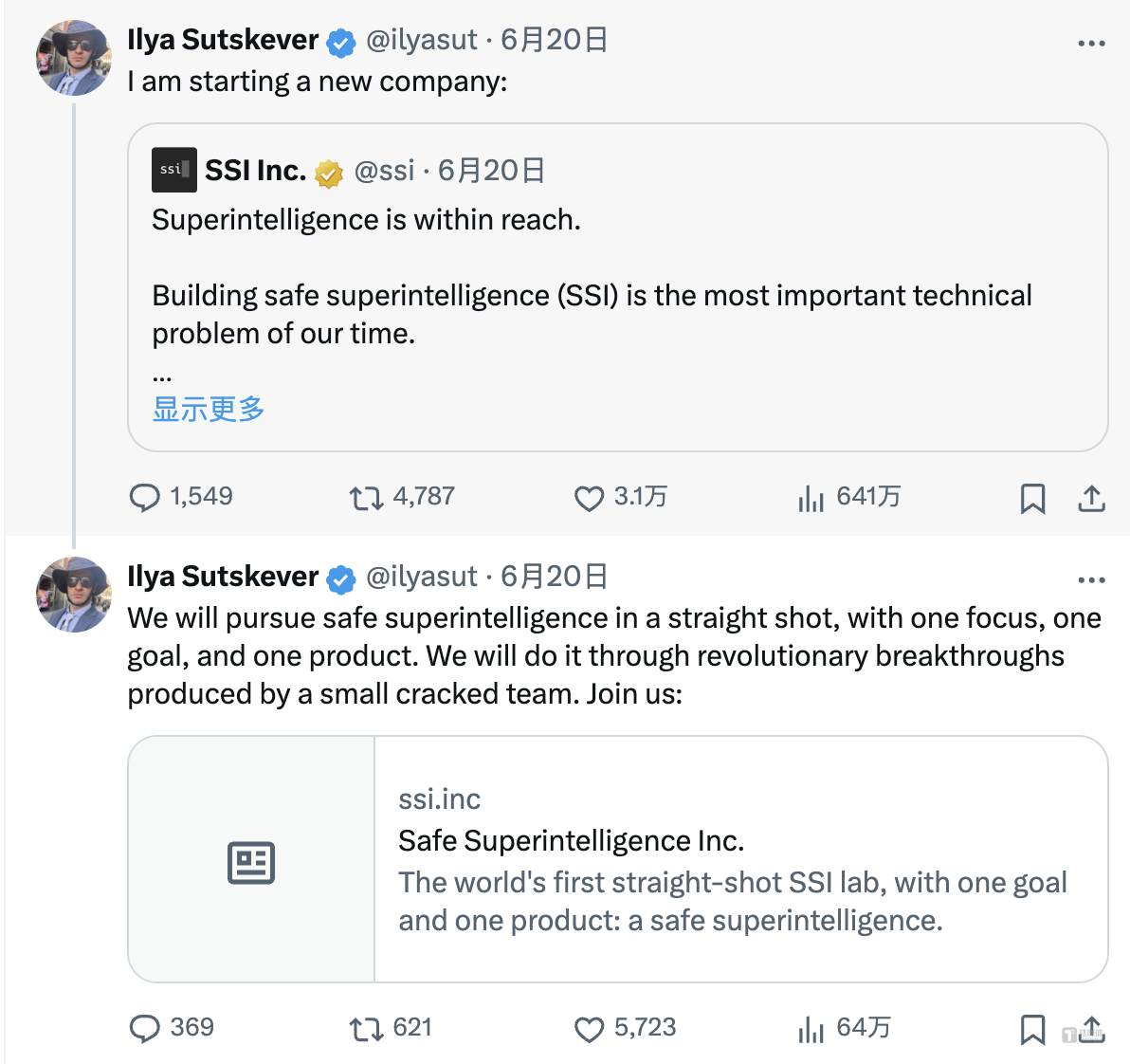
最近AI领域发生了一件重磅事件,引发广泛关注。北京时间6月20日,OpenAI联合创始人、前首席科学家伊利亚(Ilya Sutskever)在社交平台上发文宣布,将创办一家“安全超级智能公司”(Safe Superintelligence Inc.,简称SSI)。
“SSI是我们的使命、我们的名字、我们的整个产品路线图,因为它是我们唯一的焦点。我们的团队、投资者和商业模式都是以实现SSI为目标。”伊利亚、科技企业家和投资者Daniel Gross、OpenAI前科学家Daniel Levy在该公司官网发表的联合署名文章中称,“构建安全的超级智能,是我们这个时代最重要的技术问题。我们计划尽快提升能力,同时确保我们的安全始终处于领先地位。”
伊利亚透露,该公司已经启动了世界上第一个直接的安全的超级智能实验室,只有一个目标和一个产品:一个安全的超级智能。但目前,SSI并未公布公司的股东、科研团队和盈利模式。
实际上,伊利亚离开OpenAI,很大程度上就是因为与OpenAI CEO奥尔特曼(Sam Altman)为核心的管理层存在分歧,尤其是在如何驾驭超级AI、AGI(通用人工智能)安全发展等问题上存在相反的观点。
其中,奥尔特曼和OpenAI总裁Greg Brockman倾向于加速商业化,以获得更多资金来支持AI模型的算力需求,力求快速增强AI的力量;而伊利亚等人则希望AI更安全。
去年11月,双方矛盾激化,OpenAI上演“宫斗”大戏,结果奥尔特曼和Greg Brockman在短暂离职后重归OpenAI,原董事会中的多位董事离开,伊利亚则在今年5月宣布离任。

对此,国内AI安全公司瑞莱智慧(RealAI)CEO田天对钛媒体AGI等表示,奥尔特曼和伊利亚之间的分歧在于对AI安全的“路线之争”,伊利亚的新公司就是为了 AI 安全目标而设立的。
田天指出,包括伊利亚、图灵奖得主Geoffrey Hinton等人认为,AI安全问题现在已经到了“非常迫切”去解决的程度。如果现在不去做,很有可能就会错过这个机会,未来再想亡羊补牢是“没有可能性”的。
“大模型领域也是一样。虽然我们对于大模型预期非常高,认为它在很多领域都能去应用,但其实现在,真正在严肃场景下的大模型应用典型案例还是非常少的,主要问题在于 AI 安全上。如果不解决安全可控问题,对于一些严肃场景,是没有人敢去信任AI,没有人敢去用它(AI)。只有说解决安全、可信问题,AI才有可能去落地和应用。”田天表示,如果一些商业化公司对于安全问题不够重视、并毫无边界快速往前跑的话,可能会造成一系列安全危害,甚至可能对于整个全人类有一些安全风险和影响。
早在聊天机器人ChatGPT发布之前,伊利亚便提到AGI对人类社会可能的威胁。他把AGI与人类的关系,类比人类与动物的关系,称“人类喜欢许多动物,但当人类要造一条高速路时,是不会向动物征求意见的,因为高速路对人类很重要。人类和通用人工智能的关系也将会这样,通用人工智能完全按照自己的意愿行事。”
AGI,即人工智能已具备和人类同等甚至超越人类的智能,简单而言就是能说会写,具备计算、推理、分析、预测、完成任务等各类人类行为。这样的AI曾经遥远,但在OpenAI推出第四代模型GPT-4且正训练第五代模型GPT-5时,AGI看似近在咫尺。
今年以来,AI 安全问题持续引发关注。
今年1月,美国一位流行歌手被人用AI恶意生成虚假照片,在社交媒体迅速传播,给歌手本人造成困扰;2月,香港一家公司遭遇“AI变脸”诈骗,损失高达2亿元港币,据悉,这家公司一名员工在视频会议中被首席财务官要求转账。然而,会议中的这位“领导”和其他员工,实际都是深度伪造的AI影像。诈骗者通过公开渠道获取的资料,合成了首席财务官的形象和声音,并制作出多人参与视频会议的虚假场景。
整体来看,为了实现AGI目标,当前,AI系统在设计上主要面临五大安全挑战:
软硬件的安全:在软件及硬件层面,包括应用、模型、平台和芯片,编码都可能存在漏洞或后门;攻击者能够利用这些漏洞或后门实施高级攻击。在AI模型层面上,攻击者同样可能在模型中植入后门并实施高级攻击;由于AI模型的不可解释性,在模型中植入的恶意后门难以被检测。
数据完整性:在数据层面,攻击者能够在训练阶段掺入恶意数据,影响AI模型推理能力;攻击者同样可以在判断阶段对要判断的样本加入少量噪音,刻意改变判断结果。
模型保密性:在模型参数层面,服务提供者往往只希望提供模型查询服务,而不希望暴露自己训练的模型;但通过多次查询,攻击者能够构建出一个相似的模型,进而获得模型的相关信息。
模型鲁棒性:训练模型时的样本往往覆盖性不足,使得模型鲁棒性不强;模型面对恶意样本时,无法给出正确的判断结果。
数据隐私:在用户提供训练数据的场景下,攻击者能够通过反复查询训练好的模型获得用户的隐私信息。
北京智源人工智能研究院学术顾问委员会主任张宏江在2024北京智源大会上表示,过去一年大模型发展速度之快,行业纷纷探讨通用人工智能的实现路径与曙光,但AI安全问题的严重性与紧迫性不容忽视。
“当我们从不同层面 AI 能安全问题进行审视,除了对社会偏见,错误信息,潜在的工作替代或者大模型、自主机器人带来的大规模自动化而导致的工作流失,以及潜在的加速财富集中或财富两极化等问题有所了解,更应该关注 AI 可能带来新的经济体系和包括潜在的灾难性风险或误用事故,甚至可能导致延伸性的人类风险。AI 安全已有很多声明和请愿,但更重要的是明确目标、投入资源、采取行动、共同应对风险。”张宏江表示。
北京智源人工智能研究院理事长黄铁军表示,水深流急,AI安全已进入风险很突出的阶段。应对AI安全风险,需要对AGI水平和能力进行分五级,而且,人类应该致力于解决 AI 安全问题,加强与国际社会在AI安全领域的合作,确保AI技术可控,迎接安全AGI的到来。

AGI水平和能力的五个级别
生成式AI技术是一把双刃剑,如何把生成式AI的强大能力用于建立信息安全规范,将制约行业发展的“绊脚石”变为“压舱石”?业界一直在探索“用技术治理技术”的方案。
就在6月21日,瑞莱智慧推出全球首个可实时检测AI合成内容产品RealBelieve,中文名“尊嘟假嘟”。
据悉,与此前国内外AIGC检测产品被动上传检测不同,RealBelieve主要面向终端用户,能够提供主动实时检测防护,可接入视频流鉴别人脸真伪,也可在用户浏览网页内容时提供AIGC合成可能性提示。不仅可以为终端用户提供文本、图片、视频和音频多种模态的文件上传检测服务,还可以通过浏览器插件的形式实时提示用户所浏览网页的疑似AI合成内容,变被动为主动。目前,尊嘟假嘟RealBelieve已开启内测招募。
田天表示,作为国内为数不多专攻 AI 安全领域的公司,瑞莱智慧已服务百余家政务、金融等领域客户。随着AI技术的发展,安全在整个AI发展中的优先级一直在往前去走。未来 AI 技术要往超级智能方向发展的话,必须要建立整个安全体系,从而确保形成安全的超级智能技术。
“如果现在不去做好 AI 安全的话,可能后面我们就没有机会了。”田天称。