
微软公司开发了一种新的神经编解码语言模型 Vall-E,在自然度、语音鲁棒性和说话者相似性方面都超越了以前的成果。它是同类产品中第一个在两个流行基准测试中达到人类同等水平的产品,而且显然非常逼真,以至于微软不打算向公众开放。
借助 Vall-E 的基础,新的人工智能语音工具集成了两大增强功能,大大提高了性能。分组代码建模使微软能够更好地组织编解码器代码,从而缩短序列长度,提高推理速度,帮助克服与长序列建模相关的挑战。
与此同时,"重复感知采样"重新考虑了原始的核采样过程,以便在解码时寻找标记重复。微软表示,这一过程有助于稳定解码,防止出现初代 Vall-E 中出现的无限循环问题。
微软使用 LibriSpeech 和 VCTK 数据集对 Vall-E 2 进行了测试,结果它都以优异的成绩通过了测试。当雷德蒙德声称这款人工智能工具实现了与人类的平等时,他们的意思是 Vall-E 2 在鲁棒性、相似性和自然度方面的表现都优于地面实况样本。换句话说,该工具可以生成与原说话人几乎完全相同的自然语音。
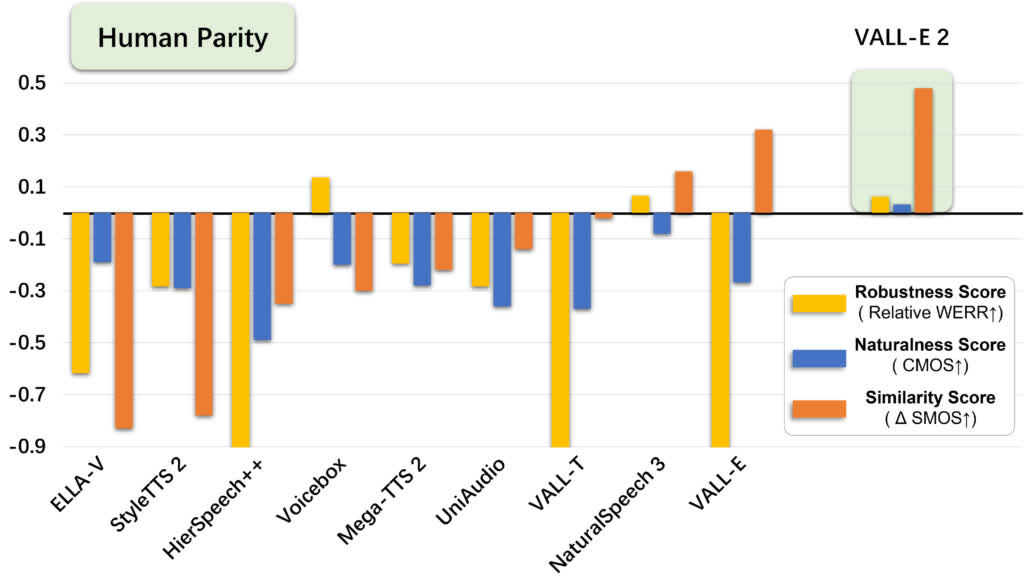
微软分享了 Vall-E 2 的数十个样本,这些样本可以在项目摘要页面上找到。事实上,Vall-E 2 的样本栩栩如生,与人类说话者毫无区别。这款人工智能工具甚至还能掌握一些微妙的技巧,比如在句子中强调正确的单词,就像人们在说话时下意识地做的那样。
微软表示,Vall-E 2 纯粹是一个研究项目,并补充说它没有计划将这项技术融入消费产品或向公众发布该工具。雷德蒙德还指出,它存在被滥用的潜在风险,例如冒充特定的人或欺骗语音识别。
不过,该公司认为,它可以应用于教育、翻译、无障碍环境、新闻、自撰内容和聊天机器人等领域。