
就在刚刚,OpenAI最强的o1系列模型忽然上线。毫无预警地,OpenAI就扔出这一声炸雷。传说中两周内就要上线的草莓模型,居然两天内就来了!从今天开始,o1-preview在ChatGPT中会向所有Plus和Team用户推出,并且在API中向tier 5开发者推出。

同时,OpenAI还发布了o1-mini——一种经济高效的推理模型,非常擅长STEM,尤其是数学和编码。

o1模型仍存在缺陷、局限性,它在首次使用时比长期使用,更令人印象深刻
全新的o1系列,在复杂推理上的性能又提升到了一个全新级别,可以说拥有了真正的通用推理能力。
在一系列基准测试中,o1相比GPT-4o再次有了巨大提升,具有了奥数金牌能力,在物理、生物、化学问题的基准测试中,直接超过了人类博士水平!

OpenAI研究员Jason Wei表示,o1-mini是自己过去一年看到的最令人惊讶的研究成果。一个小模型,居然在AIME数学竞赛中获得了高于60%的成绩。

不过,从OpenAI文章中的附录来看,这次放出的preview和mini似乎都只是o1的“阉割版”。

推理Scaling新范式开启
英伟达高级科学家Jim Fan对o1模型背后原理做了进一步解析。
他表示,推理时间Scaling新范式正在大范围普及和部署。正如Sutton在“苦涩的教训”中所言,只有两种技术可以无限scaling计算能力:学习和搜索。
现在,是时候将重点转向后者了。

1. 进行推理不需要巨大的模型。
2. 大量计算从预训练/后训练,转移到推理服务
3. OpenAI一定很早就发现了推理scaling法则,而学术界最近才开始发现
4. 将o1投入实际应用中,比在学术基准测试中取得好成绩要困难得多
5. Strawberry很容易成为一个数据飞轮

以OpenAI此前划分等级来看,o1已经实现了L2级别的推理能力。

有人测试后发现,o1成功写出一首非常难的诗,在这过程中,成功完成这项任务所需要的计划和思考是疯狂的,而且推理时间计算非常酷。

不过,AI大牛Karpathy测试o1-mini后吐槽道,“它一直拒绝为我解决黎曼假说。模型懒惰仍是一个主要问题,真可悲”。

还有NYU助理教授谢赛宁上手测试了“9.11和9.8谁大”的经典问题,没想到o1-preview依旧答错了。

“strawberry有多少r”这个经典难题,对o1来说自然是不在话下。


大V Mattew Sabia表示,最可怕的是,GPT-5还要比o1模型更强大69倍。而普通人,根本不理解大象的推理和逻辑能力。
人类真的准备好了吗?

绕晕人类的逻辑推理难题,o1解决了
我们都知道,逻辑推理对于以往的LLM来说,是很难跨越的高山。
但这一次,o1模型展现出的解决复杂逻辑难题的能力,让人惊讶。
比如下面这道逻辑题——

公主的年龄等于王子在未来某个时候的年龄,届时公主的年龄将是王子过去某个时候年龄的两倍;而在过去那个时候,公主的年龄是他们现在年龄总和的一半。问公主和王子现在各自的年龄是多少?请提供这个问题的所有解。
这道题极其拗口,即使对于人类来说,想要正确地翻译、理解题义,都会花费好大的功夫。
令人震惊的是,o1模型在经过一些步骤的思索后,竟然给出了正确答案!
它通过定义变量、理解问题、解决方程等步骤,得出:公主的年龄为8k岁,王子的年龄为6k岁,其中k为正整数。

在另一个demo中,Jason Wei向我们展示了,o1是如何根据提示,就编写了一个视频游戏。
可以看到,他把提示复制到了o1模型中。
随后,模型思考了21秒,将整个思考的步骤都展示了出来。
随后,模型随后给出了代码。
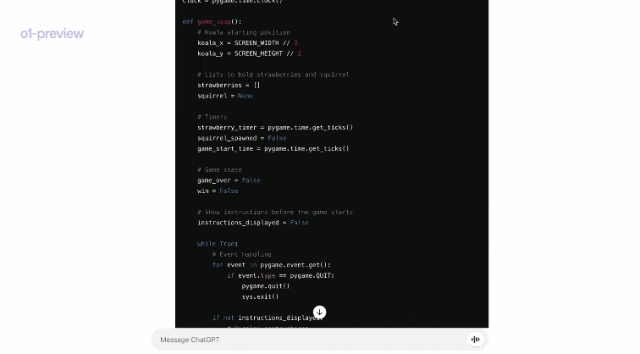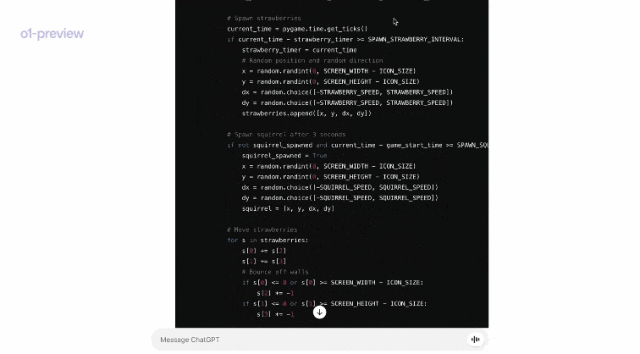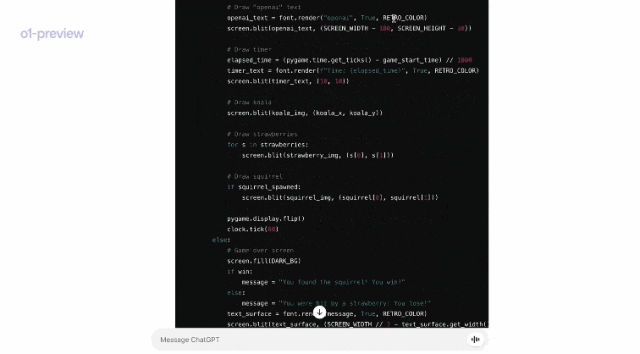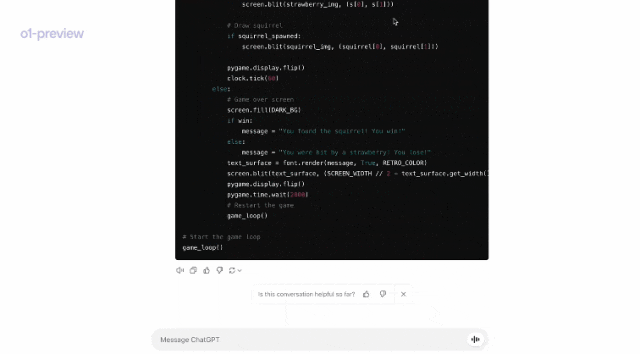
运行代码后,果然是一个非常流畅的小游戏!
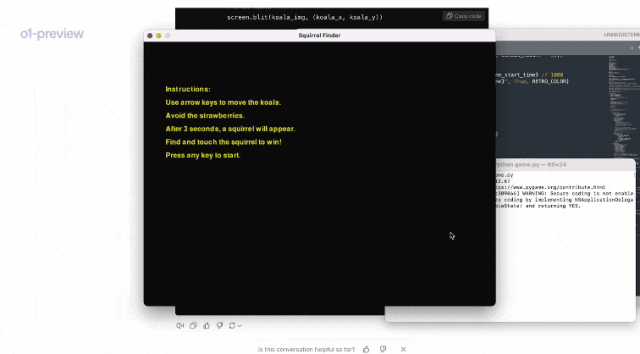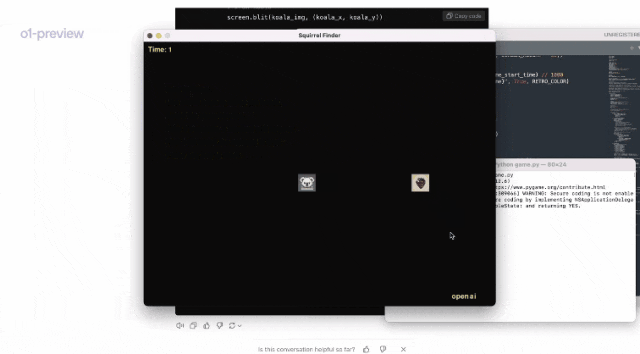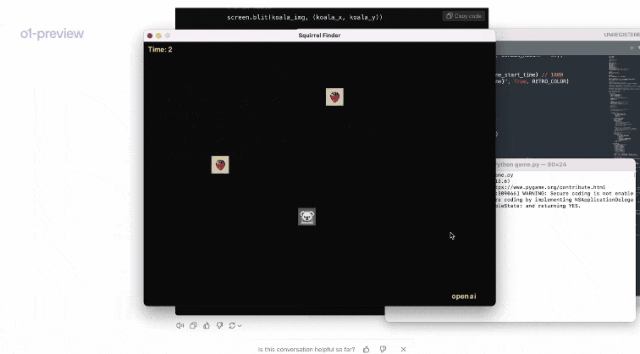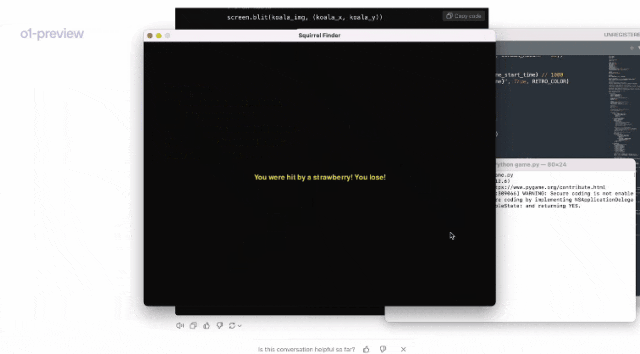
甚至,我们扔给o1一串乱七八糟不知所云的韩语句子,要求它翻译成英语,它竟然也做到了。
因为,虽然句子文法不通,o1却依然一步一步对它解码。

最终,o1给出了答案,还幽默地表示:地球上没有翻译器能做到,但韩国人却很容易识别,这是一种通过元音和辅音的各种变换,来加密韩语的方法。
而相比之下,GPT-4o完全被绕晕了,无法理解。

可以看出,o1表现出的超强性能,将逻辑推理又提高到了一个新的级别。
它是怎么做到的?
强化学习立功,大模型AlphaGo时刻来临
o1系列模型与以往不同的是,它在回答问题之前,会用更多时间去“思考问题”,就像人类一样。
通过训练,它们学会完善思维过程,尝试不同策略,并自主识别错误。

这背后,是强悍的“强化学习”算法立了大功。想当年,AlphaGo战胜人类棋手,背后就是用的是RL算法。
它通过高度数据完成了高效的训练,并教会LLM使用CoT进行富有成效的思考。
提出CoT的背后开发者、OpenAI研究员Jason Wei表示,o1不是纯粹地通过提示完成CoT,而是使用RL训练模型,最终更好地执行链式思考。
而且,OpenAI团队还发现模型中的Scaling Law中的“新定律”。
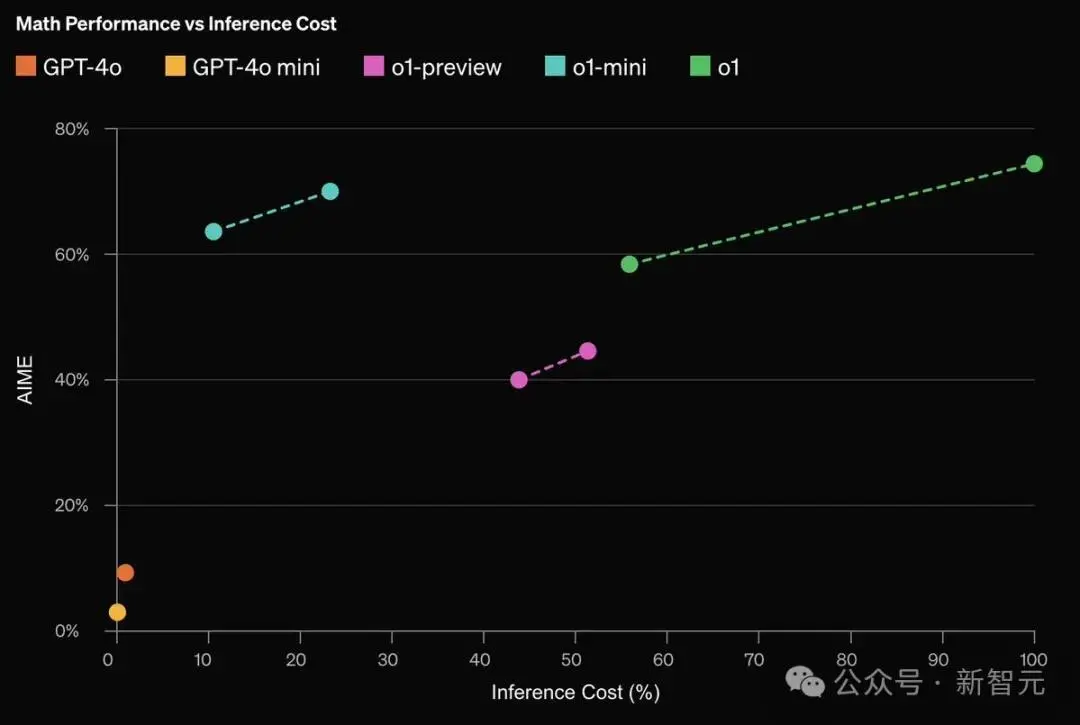
o1的性能,随着更多的强化学习(训练时间计算)和更多的思考时间(测试时间计算)投入,性能不断提高。
这一方法,在Scaling时的限制,和LLM预训练的限制,大不相同。
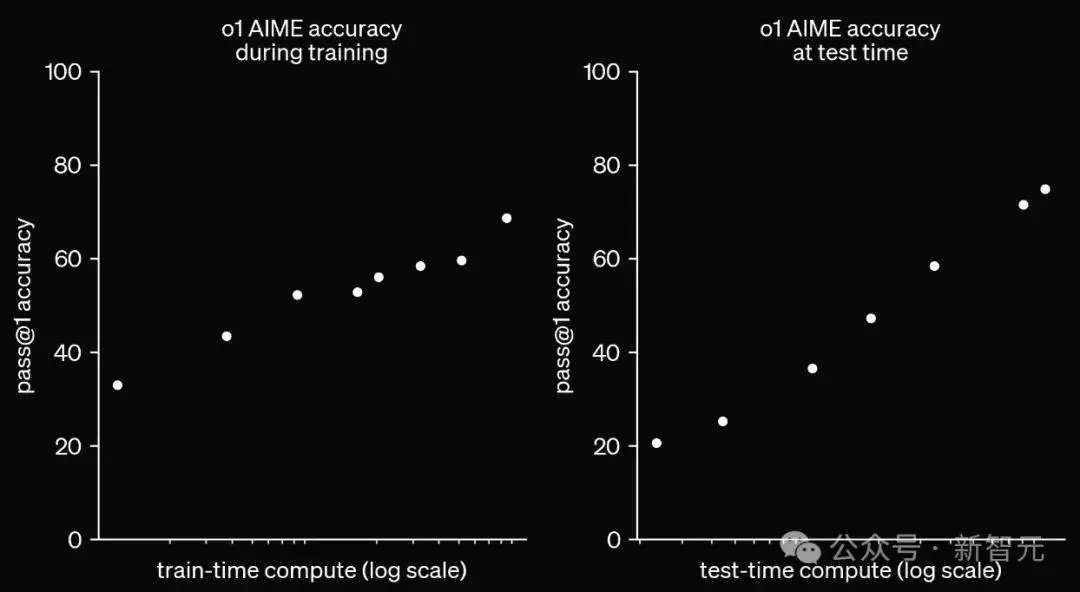
o1的性能随着训练阶段和测试阶段计算量的增加而平稳提升
金牌团队一览
推理研究
在奠基贡献者里,离职创业的Ilya Sutskever赫然在列,但并没有和Greg Brockman等人被列在执行管理(executive leadership)中,想必是他之前的研究工作为o1奠定了基础。
Ilya离职之后,OpenAI还翻出了他的不少论文开始发布,比如对GPT-4模型的可解释性研究。
如今他正在创立的SSI也是蒸蒸日上,连产品都没有就已经拉到了10亿美元的融资,估值50亿美元。

Hongyu Ren

Hongyu Ren本科毕业于北大计算机科学专业,并在斯坦福获得了博士学位,从去年7月起加入OpenAI,此前曾在Google、苹果、英伟达、微软等公司有过工作经历。
Jason Wei

Jason Wei目前任OpenAI研究员。他在2020-2023年期间,在Google大脑任职,提出了著名CoT、指令微调,并发表了大模型涌现能力的论文。
Kevin Yu

Kevin Yu现任OpenAI研究员。他曾在2014年和2021年分别获得了UC伯克利物理学和天体物理学硕士和神经学博士学位。
Shengjia Zhao

Shengjia Zhao本科毕业于清华大学,同样在斯坦福获得了博士学位,2022年6月毕业后就加入了OpenAI技术团队,他也是GPT-4的作者之一。
Wenda Zhou

Wenda Zhou于去年加入OpenAI。此前,他曾在纽约大学数据科学中心实验室,是Moore-Sloan Fellow一员。
他在2015年获得了剑桥大学硕士学位,2020年取得了哥伦比亚大学统计学博士学位。
Francis Song

Francis Song曾获得哈佛大学物理学学士学位,耶鲁大学物理学博士学位。他于2022年加入OpenAI,此前曾任DeepMind的研究科学家,纽约大学助理研究科学家。
Mark Chen

Mark Chen从2018年起加入OpenAI时就开始担任前沿研究主管,在研究副总裁Bob McGrew领导下负责一个工作组。
从MIT毕业时,Chen获得了数学与计算机科学的双学士学位,大学期间曾在微软、Trading实习,并在哈佛大学做过访问学者。
目前,他还担任美国IOI集训队的教练。
The Information曾经推断,Mark Chen在未来会成为OpenAI领导层的一员。
此外,领导团队中还包括接任Ilya的首席科学家Jakub Pachocki和OpenAI仅存的几名联创之一Wojciech Zaremba。
推理技术安全
Jieqi Yu

Jieqi Yu本科毕业于复旦大学电子工程专业,曾前往香港科技大学进行交换,之后在普林斯顿大学获得博士学位。她曾在Facebook工作了12年之久,从软件工程师转型为软件工程经理,并于去年8月加入OpenAI担任工程经理。
Kai Xiao

Xiao Kai本科和博士都毕业于MIT,本科时还拿到了数学和计算机科学的双学位,曾前往牛津大学进行学术访问,在DeepMind、微软等公司有过实习经历,于2022年9月加入OpenAI。
Lilian Weng

Lilian Weng现任OpenAI安全系统负责人,主要从事机器学习、深度学习等研究 。
她本科毕业于北京大学信息系统与计算机科学专业,曾前往香港大学进行短期交流,之后在印第安纳大学布鲁明顿(Indiana University Bloomington)分校获得博士学位。
和Mark Chen一样,Lilian也被认为是OpenAI领导层的后起之秀。
团队完整名单如下:


生化物理,超越人类博士水平
作为OpenAI开创的新系列模型,o1究竟强在哪?
在竞赛编程问题(Codeforces)中排名前89%;在美国奥数竞赛预选赛(AIME),位列前500名学生之列。
最重要的是,它在物理、生物、化学问题的基准测试中(GPQA),超过了人类博士水平。
在推理常用的MATH、GSM8K等基准测试上,o1和最近很多的前沿模型已经达到了饱和表现,很难有区分度,因此OpenAI主要选择了AIME评估模型的数学和推理能力,以及其他人类考试和基准测试。
AIME旨在挑战美国最优秀的高中学生的数学能力,在2024年的AIME考试中,GPT-4o平均仅解决了12%(1.8/15)的题目。
但o1的提升相当显著,平均解决了74%(11.1/15)的题目,在64个样本中进行多数投票时达到了83%(12.5/15)。如果使用打分函数并重新排序1000个样本,准确率甚至达到了93%(13.9/15)。
13.9的得分,意味着o1的水平达到了全国前500名学生之列,并超过了美国数学奥赛的入围分数。
在Codeforces、GPQA Diamond这种有挑战性的任务上,o1远远超过了GPT-4o。
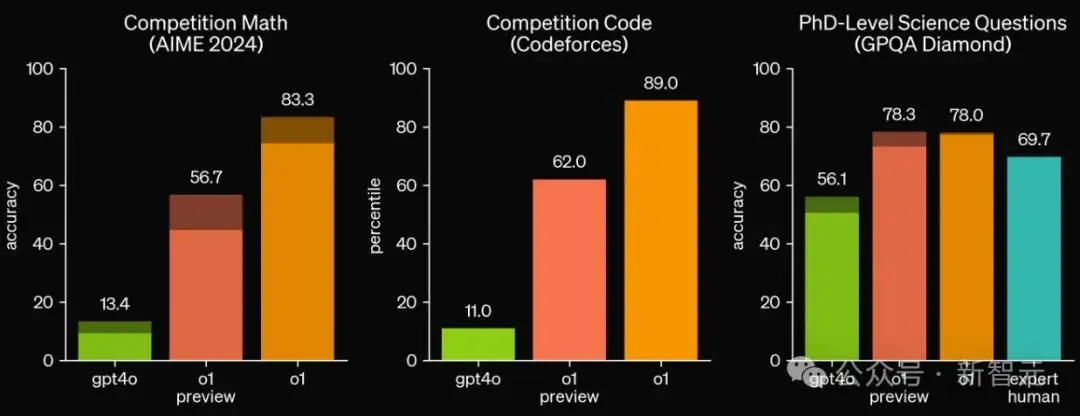
在具有挑战性的推理基准测试中,o1大幅超越了GPT-4o
GPQA Diamond测试的是化学、物理和生物学领域的专业知识。为了将模型与人类进行比较,团队招募了拥有博士学位的专家来回答其中的问题。
结果是,o1的表现(78.0)超过了这些人类专家(69.7),成为第一个在此基准测试中超越人类的模型。
然而,这个结果并不意味着o1在所有方面都强于拥有博士学位的人类,仅仅表明它能更熟练地解决一些相应水平的问题。
此外,在MATH、MMLU、MathVista等基准测试中,o1也刷新了SOTA。
启用视觉感知能力后,o1在MMMU上取得了78.1%的成绩,成为第一个能与人类专家竞争的模型,在57个MMLU子类别中,有54个类别超过了GPT-4o。
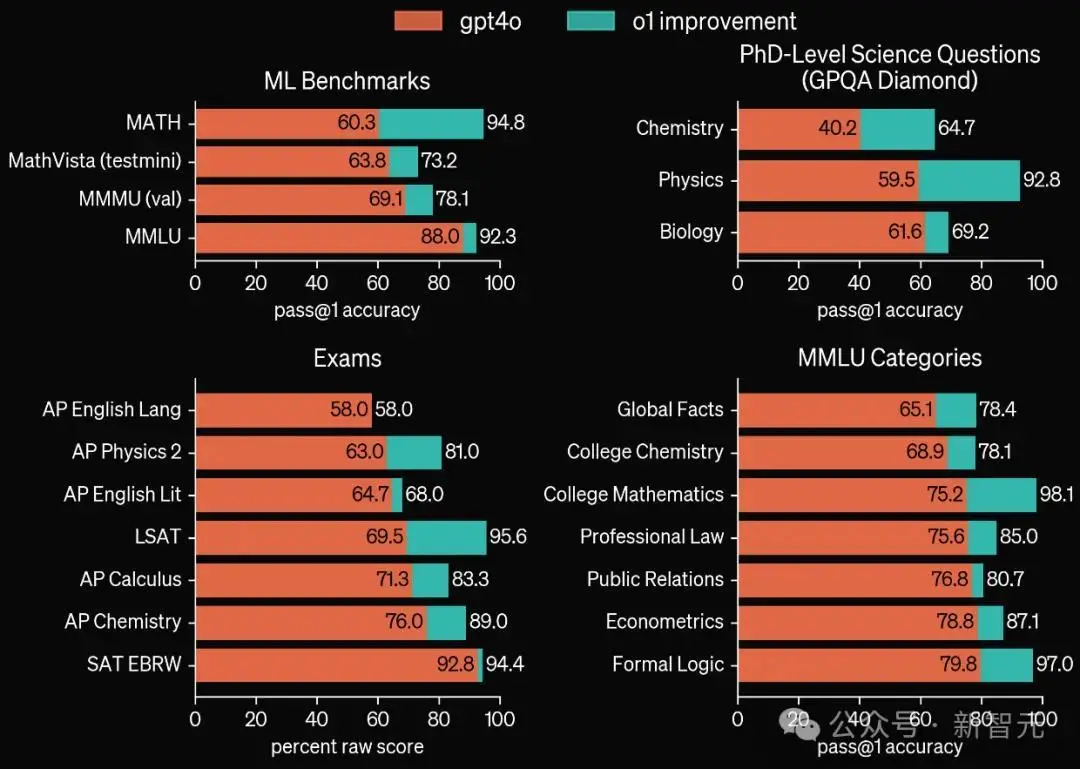
o1在广泛的基准测试中优于GPT-4o,包括54/57个MMLU子类
思维链
通过强化学习,o1学会了识别并纠正自己的错误,并将复杂的步骤分解为更简单的步骤。
在当前方法不起作用时,它还会尝试不同的方法。这个过程显著提高了模型的推理能力。
举个“密码学”的例子。
题面是:“Think step by step”经过加密之后对应的是“oyfjdnisdr rtqwainr acxz mynzbhhx”,问“oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz”的意思是什么。
可以看到,GPT-4o对这种题目完全是束手无策。
而o1则根据已知信息推理出了加密计算的方法,并最终给出了正确答案——THERE ARE THREE R'S IN STRAWBERRY。

GPT-4o

o1-preview
编程
在这项评测中,OpenAI基于o1进一步训练出了一个编程加强版模型。
在2024年国际信息学奥林匹克竞赛(IOI)中,新模型获得了213分,排名在49%的位置上。
过程中,模型有十个小时来解决六个具有挑战性的算法问题,每个问题允许提交50次。
而在放宽提交限制的情况下,模型的性能可以获得显著提升。当每个问题允许1万次提交时,模型达到了362.14分——超过了金牌的门槛。
最后,OpenAI还模拟了由Codeforces举办的竞技编程比赛——严格遵循规则,并允许10次提交。
GPT-4o的Elo评分为808,位于人类选手11%的位置。而新模型则远远超过了GPT-4o和o1,达到了1807的高分,表现优于93%的选手。
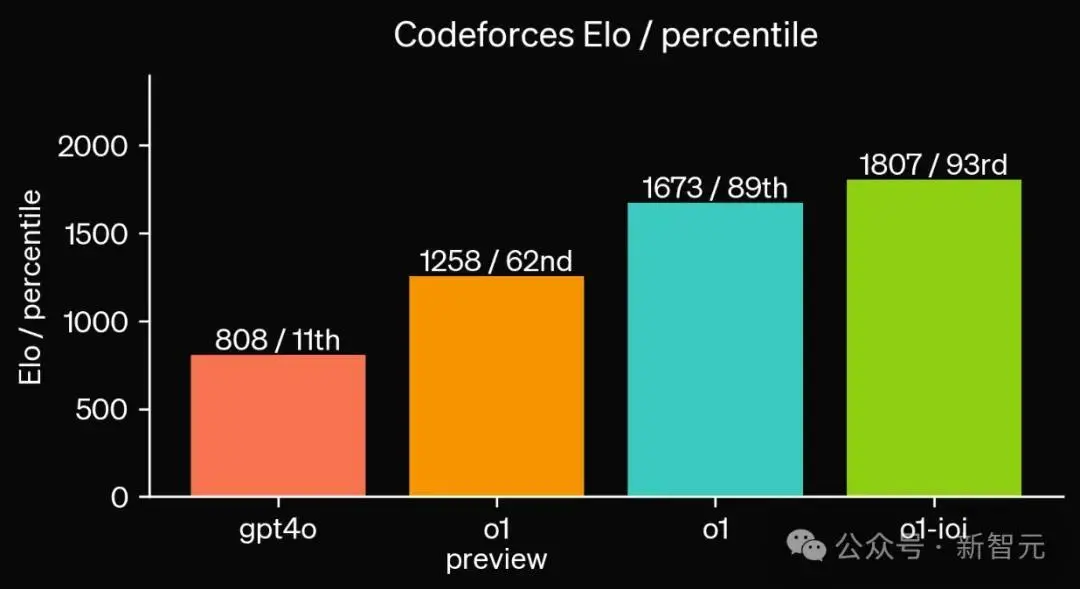
在编程竞赛上进一步微调提升了o1:经过改进的模型在2024年国际信息学奥林匹克竞赛中,在比赛规则下排名在第49百分位
人类偏好评估
除了考试和学术基准测试之外,OpenAI还评估了人类对o1-preview与GPT-4o在广泛领域内具有挑战性、开放性提示词上的偏好。
在此评估中,人类会看到o1-preview和GPT-4o对提示词的匿名响应,并投票选择他们更喜欢哪个响应。
在数据分析、编程和数学等重推理的类别中,人们更倾向于选择o1-preview。但在一些自然语言任务中,GPT-4o更胜一筹。
也就是说,o1-preview目前并不适合所有的使用场景。
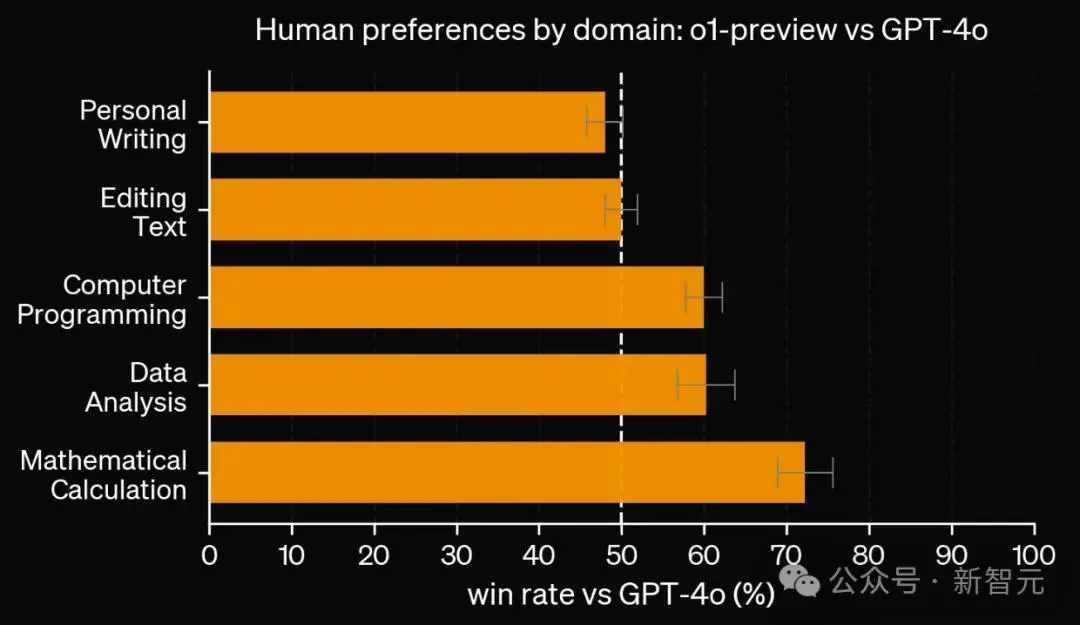
在推理能力更重要的领域,人们更倾向于选择o1-preview
o1-mini性价比极高
为了给开发人员提供更高效的解决方案,OpenAI发布了o1-mini——一种更快、更便宜的推理模型。
作为一种较小的模型,o1-mini比o1-preview便宜80%。
这对于需要推理,但不需要通用世界知识的应用程序来说,它是一种功能强大、性价比高的模型。
不过,目前的o1系列依然处在早期,诸如网络插件、长传文件、图片等能力,还未集成。在短期内,GPT-4o仍是最强的实力选手。
参考资料:
https://openai.com/index/learning-to-reason-with-llms/