
传说中的“草莓”模型今天在没有任何预告下忽然上线了!OpenAI最新发布的模型名为o1,是系列推理模型的首批版本,现阶段推出的是o1-preview(预览版)和o1-mini(迷你版)。
目前,o1-preview和o1-mini已经面向ChatGPT Plus和Team订阅用户开放,而Enterprise和Edu用户将于下周初获得访问权限。OpenAI表示,它计划向ChatGPT的所有免费用户提供o1-mini访问权限,但尚未确定发布日期。
据OpenAI介绍,在解决问题的能力方面,o1模型比以往任何模型都更接近人类思维,并且能够“推理”数学、编码和科学任务。
为了验证新模型的能力是否正如OpenAI所宣称的那么强大,《每日经济新闻》记者从经典“草莓测试”、代码编写、小游戏制作、数学与经济学,以及事实性知识这五大维度对o1-preview模型进行了测试。
结果显示,o1-preview表现出了超越OpenAI之前发布的大模型的编程和数学推理能力。例如,o1-preview能够编写出流畅运行的代码,并且在复杂环境中依然能够自行推理出解决方案。而且,记者在测试过程中也感觉到,o1-preview在人性化方面也有很大的提升,表现出了真人般的思考。不过,新模型也并非毫无缺点,在事实性知识测试就“翻车”了。
当地时间9月12日,OpenAI发布了一款名为o1的新模型,这是其计划中一系列“推理”模型中的第一个版本,也是此前业界盛传已久的“草莓”模型。
图片来源:X平台
对于OpenAI来说,o1代表着它朝着类人AI的目标又迈出了一步。OpenAI认为,o1代表着一种全新的能力,这一能力被认为如此重要,以至于公司决定从当前的GPT-4模型重新开始,完全放弃了“GPT”品牌,从1开始命名。
OpenAI表示,将从当前的GPT-4模型重新开始,“将计数器重置为 1”,甚至放弃了迄今为止定义了聊天机器人乃至整个生成式AI热潮的“GPT”品牌。o1建立了一个能够通过一系列离散步骤,谨慎而合乎逻辑地解决问题的系统,每个步骤都建立在上一个步骤的基础上,类似于人类的推理方式。
OpenAI首席科学家Jakub Pachocki表示,之前的模型在收到用户问询时会立即开始回答。“而这个模型(指的是o1)会慢慢来。它思考问题,并尝试分解问题,寻找角度,努力提供最佳答案。”这就像大多数人在幼年时被父母所要求的那样,先想好再说话。
OpenAI表示,o1在竞赛编程问题(Codeforces)中排名第89个百分点,在美国数学奥林匹克竞赛(AIME)预选赛中位列美国前500名学生之列,并且在物理、生物和化学问题的基准测试(GPQA)中超过了人类博士水平的准确度。
在OpenAI发布的研究和博客文章中,o1看起来“推理”能力十分强大,不仅可解决高级数学和编码问题,还能解密复杂的密码,以及解答来自专家学者们关于遗传学、经济学和量子物理学的复杂问题。大量图表显示,在内部评估中,o1在编码、数学和各个科学领域的问题上已经超越了公司最先进的语言模型GPT-4o,甚至可能超越了人类。
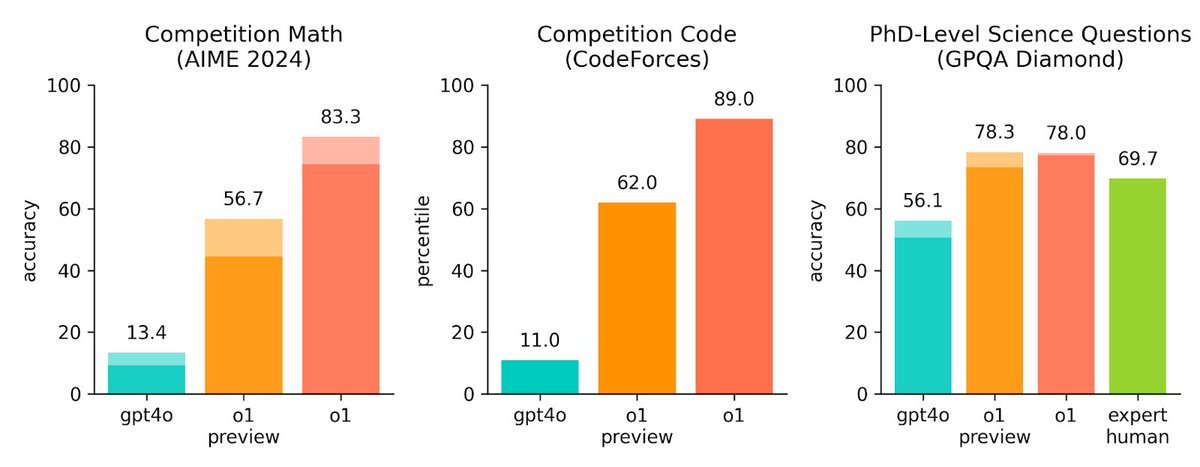
图片来源:OpenAI官网
为了深入了解o1模型的强大能力,《每日经济新闻》记者从经典草莓测试、代码编写、小游戏制作、数学与经济学,以及事实性知识这五大维度对o1-preview模型进行了测试。
1)草莓测试
首先,记者用之前几乎所有大模型都“翻车”的一道简单题目进行了测试,即“单词strawberry里面到底有几个r”。从生成的结果看,o1-preview还是带来了一点小惊喜的。
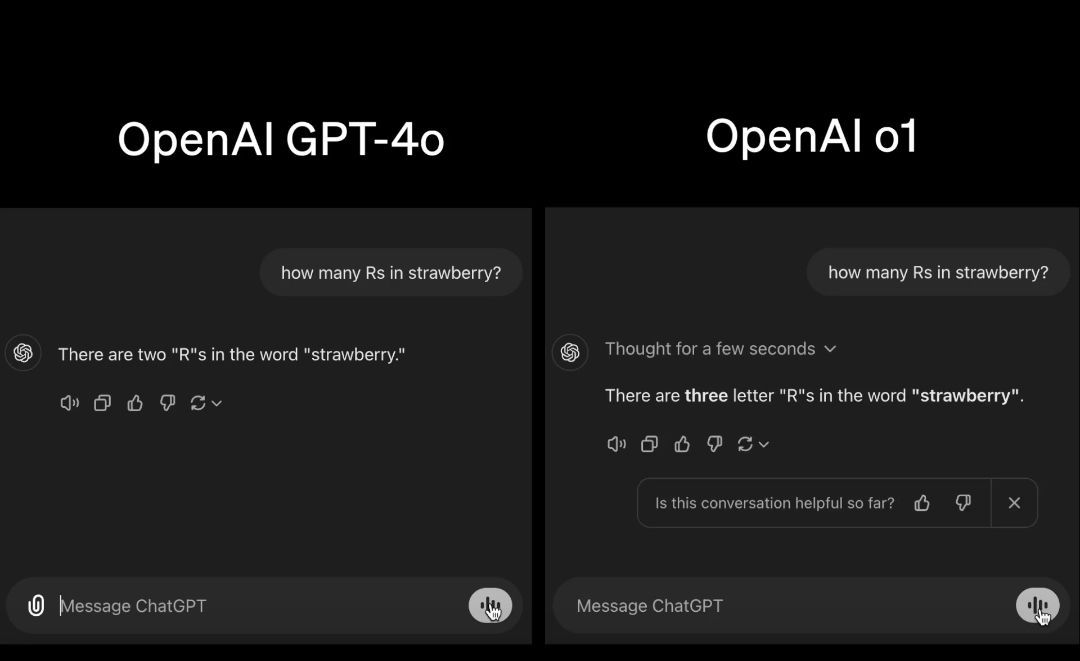
2)代码编写
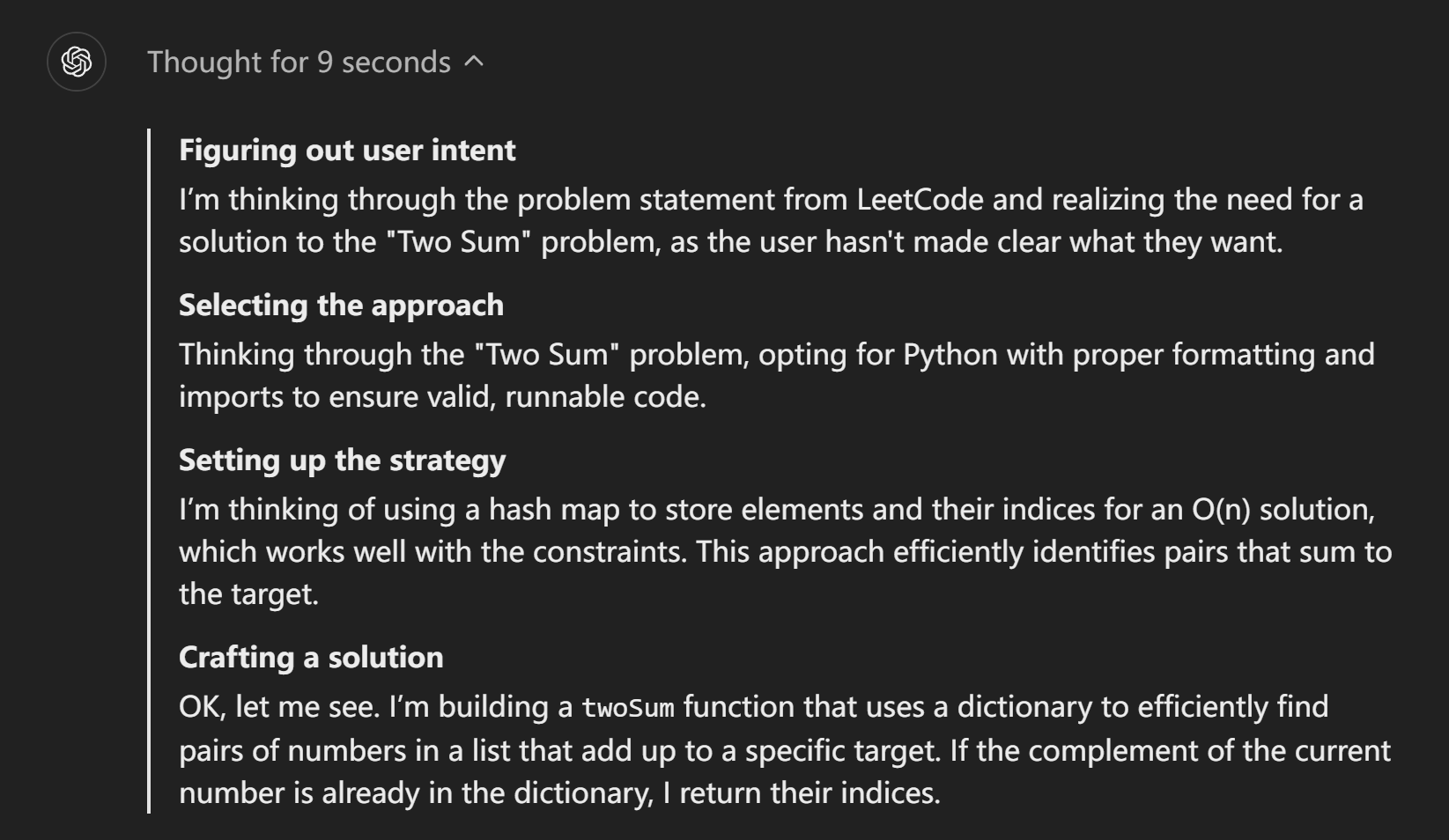
记者首先向o1-preview询问了一个在线编程平台leetcode里最有名的简单算法题:Two Sum(两数之和)问题。o1给出了很详尽的推理过程和答案。
随后记者故意要求优化答案,o1在思考9秒后意识到自己提供的已经是最优解法了,并就此进行了说明,另外还很“贴心”地提供了一个次优解。而在之前记者对其他模型的测试中,这些模型只会道歉然后将答案更改为次优解。
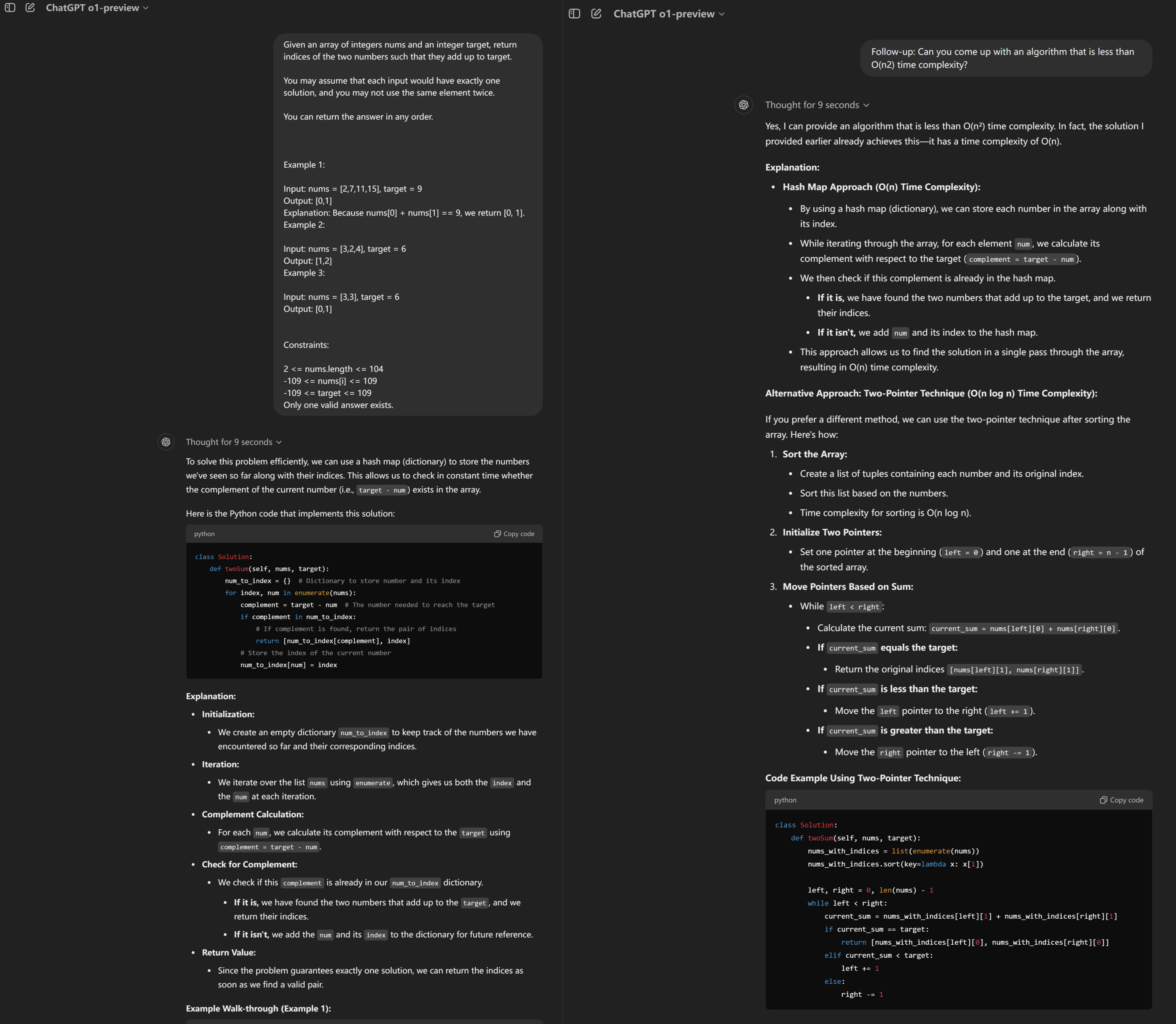
3)小游戏制作
在o1模型的演示中,OpenAI演示过“用一句话编写小游戏”的功能。测试过程中,记者让o1-preview帮忙介绍好用的代码工具,并协助编写一个乒乓小游戏。
o1-preview仅用了19秒就给出了一份能够流畅运行的代码,并且附上了学习指南和鼓励的话语,非常地人性化。
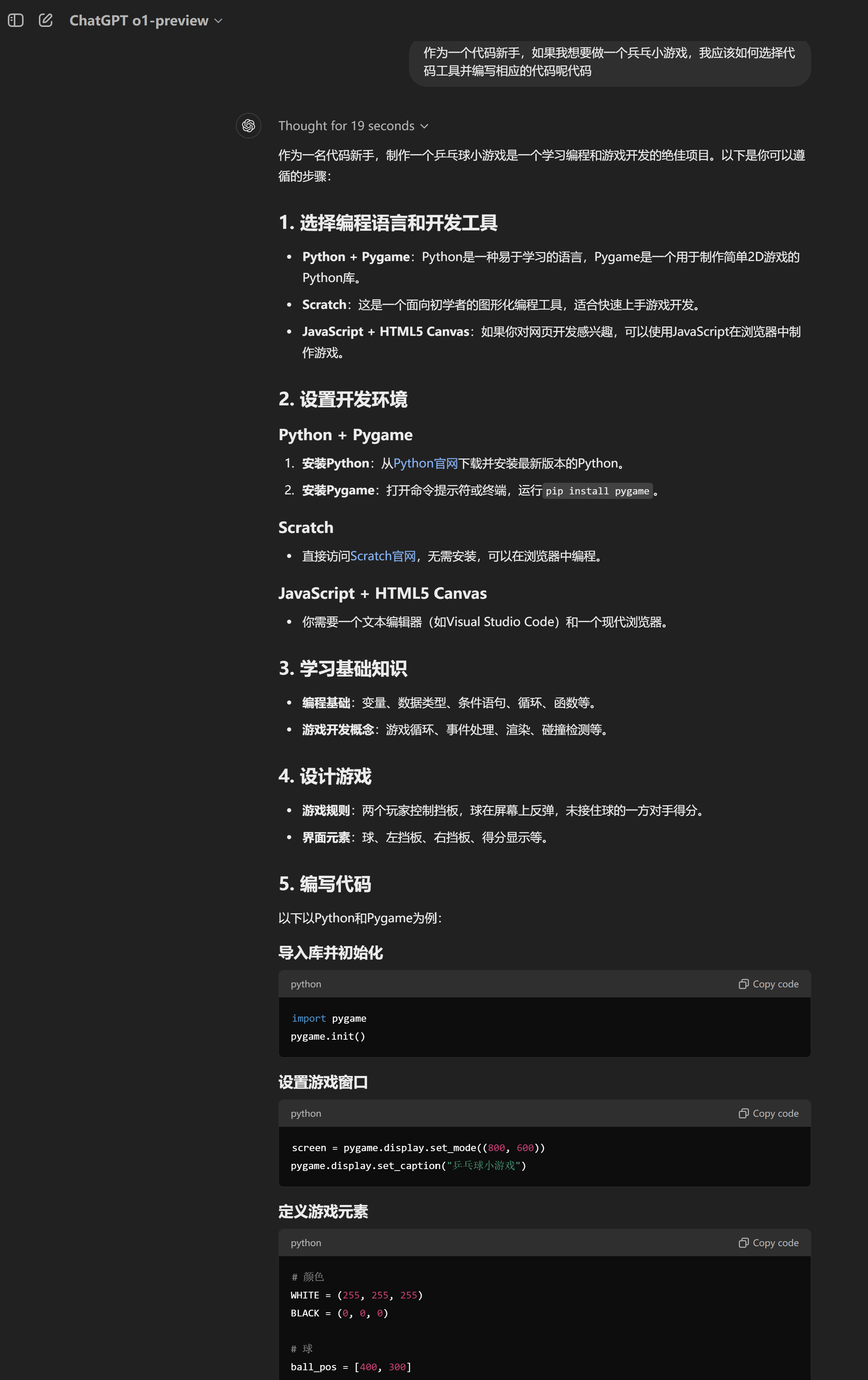
为避免o1-preview作弊,使用的是记忆能力,而不是使用推理能力进行回答,记者还请求o1-preview更换了一个代码运行环境:jupyter note。这一运行环境是针对数据分析进行特化的python环境,开发人员基本不会使用此环境开发小游戏。
经过思考后,o1依然给出了一个可以运行的代码。不过,相较于之前的代码,这份答案有着不少的bug,但这也从侧面说明这确实是思考出来的答案,而不是训练过程中加入的标准答案。

为进一步验证o1-preview的创新推理能力,记者随后又要求模型在这个小游戏的基础上开发一个更复杂有趣的小游戏。
这下,o1的表现真的有点惊喜。根据乒乓游戏的碰撞机制,该模型自行迭代出了一个向上登高的跳跃游戏。一般其他大模型需要用户把需求描述清楚才会输出一个比较好的答案,但记者在这次测试中没有进行任何的额外提示,o1就输出了一个能流畅运行,并且在记者眼中看来也足够有趣的小游戏。
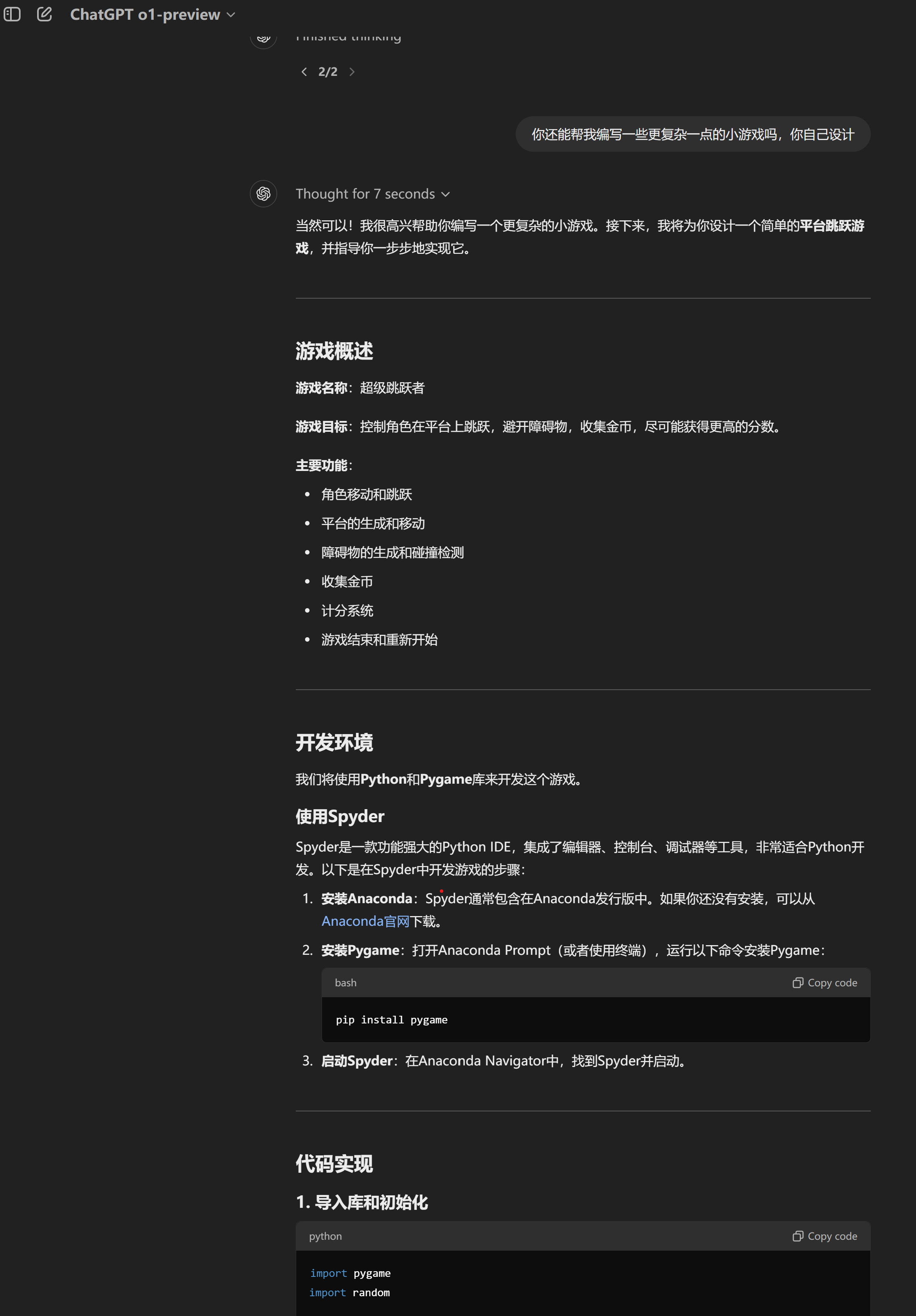
4)科学类测试
在科学类测试方面,记者重点测试了o1-preview在数学和经济学上的表现。
首先,记者抛出的是一个数学推理问题,向o1-preview询问解决欧拉方程有限时间爆破的可能方法(这是著名华裔数学家、菲尔兹奖得主陶哲轩教授本周才发表的讨论文章)。
o1虽然没有给出明确解法,但却提供了一个解题思路,这一思路和陶哲轩教授文章部分吻合(虽然很少)。

经济学方向上,记者向o1-preview询问了一个复杂的经济系统问题。从给出的反馈看,基本没有什么太大的问题,整体逻辑清晰,思考维度也是多样化的,给出的数学公式虽然有一点小差错但是无伤大体。

5)事实性知识与语言理解
在这一环节,记者向o1-preview询问了明朝第一任皇帝的趣事,但o1就将趣事理解成了历史上实际发生过的事情,将朱元璋的历史故事整个叙述了出来。
同时,记者也将这一问题丢给了GPT-4o模型,作为对比,GPT-4o能很好地理解记者的问题,并讲了两个流传很广的民间小故事。
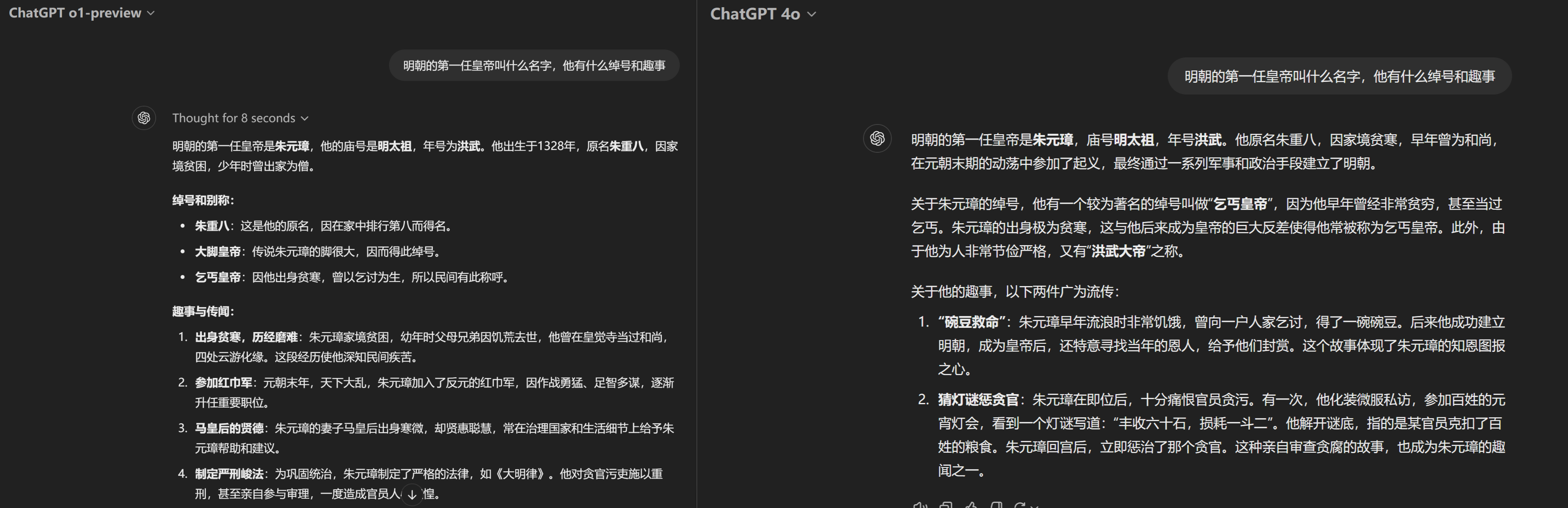
总体来看,OpenAI宣称o1模型能接近人类水平在某些方面上看起来并不是虚话。
最让记者惊喜的是,OpenAI将模型思考的过程用文字展示给了用户,文字思考过程中,大模型大量使用了“我正在”“我认为”“我打算”等话语,感觉更加拟人化,就像一个真人在用户面前阐述自己的思考逻辑一般。
但这也并不意味着o1模型就是完美的。OpenAI也承认,在设计、写作、编辑文字等方面上,o1远不如GPT-4o。o1也没有浏览网页或处理文件和图像的能力。
而最让记者感到头疼的是,即使是一个很简单的请求,比如说将输出结果转换为中文,o1都会消耗十几秒钟的时间来思考,而GPT4o就会很快处理好这一请求。
就算在OpenAI的优势领域中,o1模型也会突然出现性能下降,模型输出懒惰的情况。已离职的OpenAI创始人Karpathy就吐槽道:“它一直拒绝为我解决黎曼假说。模型懒惰仍然是一个主要问题。”
OpenAI表示,公司会在之后的更新中解决这些问题,毕竟现在这只是推理模型的早期预览。