

大语言模型真的可以推理吗?LLM 都是“参数匹配大师”?苹果研究员质疑 LLM 推理能力,称其“不堪一击”!苹果的研究员 Mehrdad Farajtabar 等人最近发表了一篇论文,对大型语言模型 (LLM) 的推理能力提出了尖锐的质疑,他认为,LLM 的“推理” 能力,其实只是复杂的模式匹配,不堪一击!

论文作者研究了包括 Llama、Phi、Gemma、Mistral 等开源模型,以及 GPT-4o 和 o1 系列等闭源模型。需要指出的是,在 OpenAI 发布 GSM8K 的三年里,模型的性能有了显著提升,从 GPT-3 (175B) 的 35% 提升到了现在 30 亿参数模型的 85% 以上,更大的模型甚至超过了 95%。但 Farajtabar 认为,这并不能证明 LLM 的推理能力真的提高了
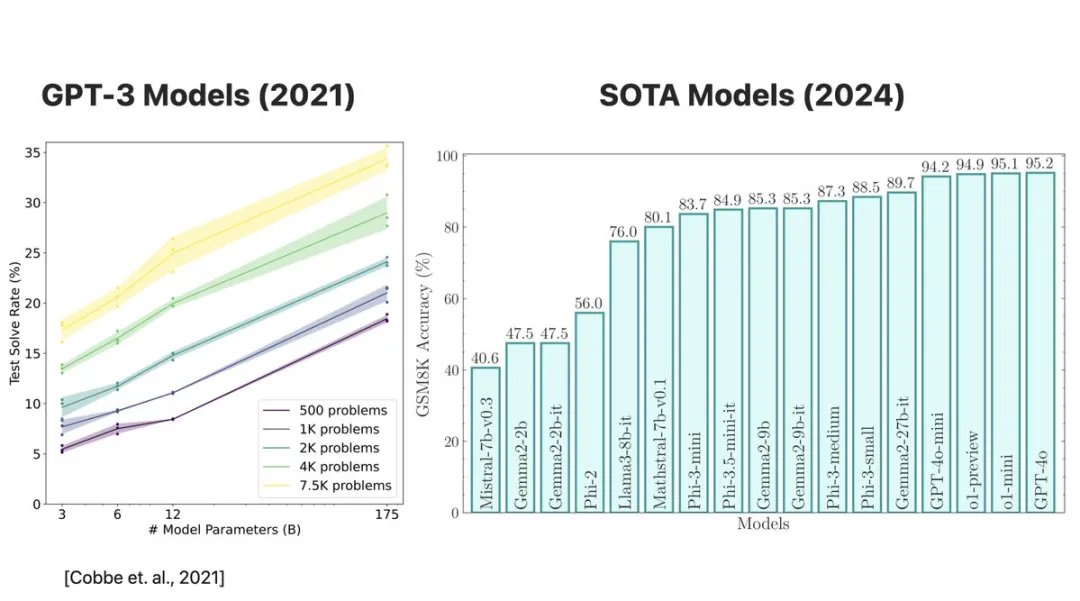
为了测试 LLM 的数学推理能力的极限,Farajtabar 和他的团队开发了一个名为 GSM-Symbolic 的新工具,它可以根据 GSM8K 测试集创建符号模板,从而能够生成大量实例并设计可控实验。他们生成了 50 个独特的 GSM-Symbolic 集合,这些集合本质上就像 GSM8K 示例,但具有不同的值和名称

GSM8K 是 “Grade School Math 8K” 的缩写,是一个用来评估数学问题解决能力的数据集。这个数据集主要包含小学级别的数学题目(大约 8,000 道题目),通常用于训练和测试机器学习模型,特别是在自然语言处理领域的模型如何处理和解决数学问题
实验结果,令人大跌眼镜:
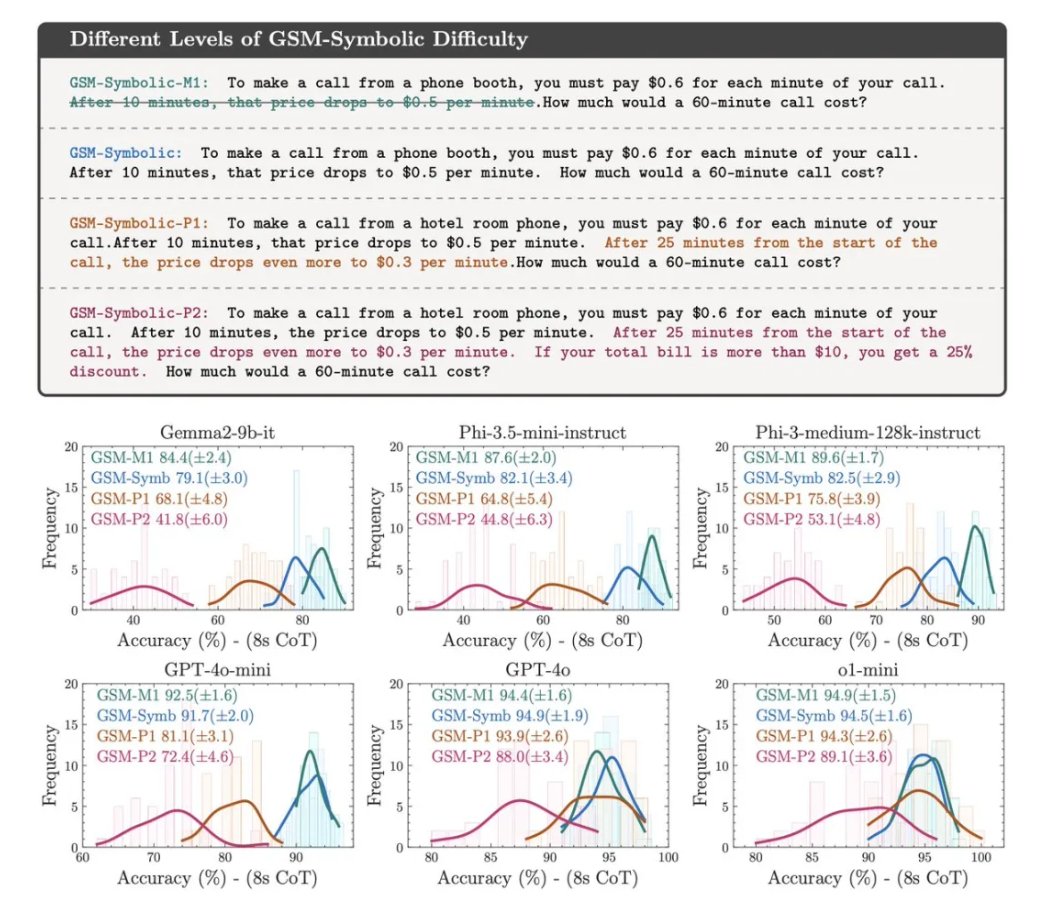
1.当前 GSM8K 的准确率并不可靠! 不同模型在 GSM8K 上的表现差异巨大,例如 Llama 8B 的得分在 70% 到 80% 之间,Phi-3 的得分在 75% 到 90% 之间,等等。对于大多数模型,在 GSM-Symbolic 上的平均性能低于在 GSM8K 上的平均性能
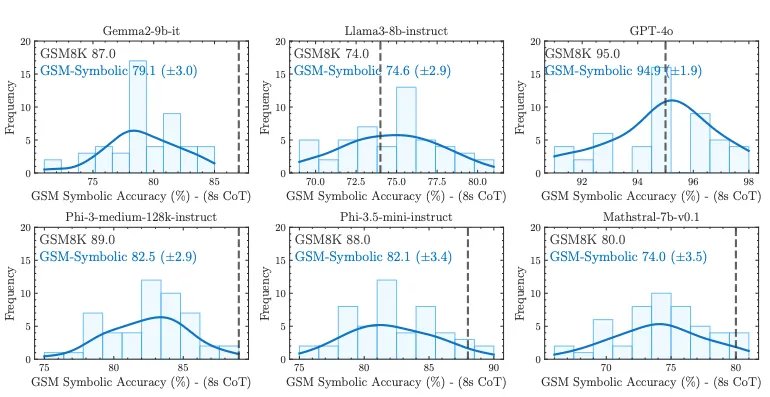
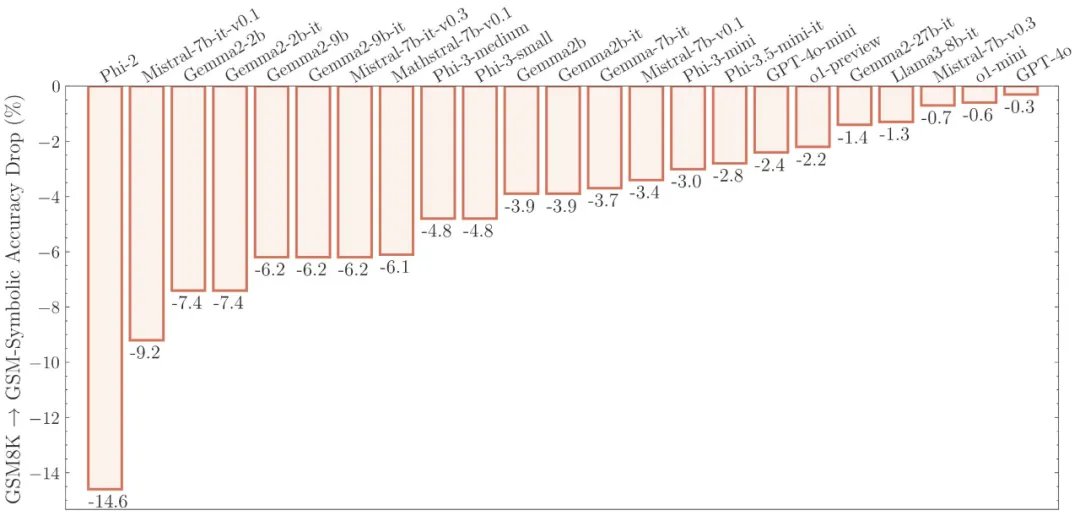
2.所谓的 LLM 推理能力不堪一击! LLM 对专有名词和数字的更改非常敏感,这说明它们并没有真正理解数学概念。就像一个小学生,如果我们只是更改了数学测试题中的人名,他的分数就会下降 10% 吗?显然不会
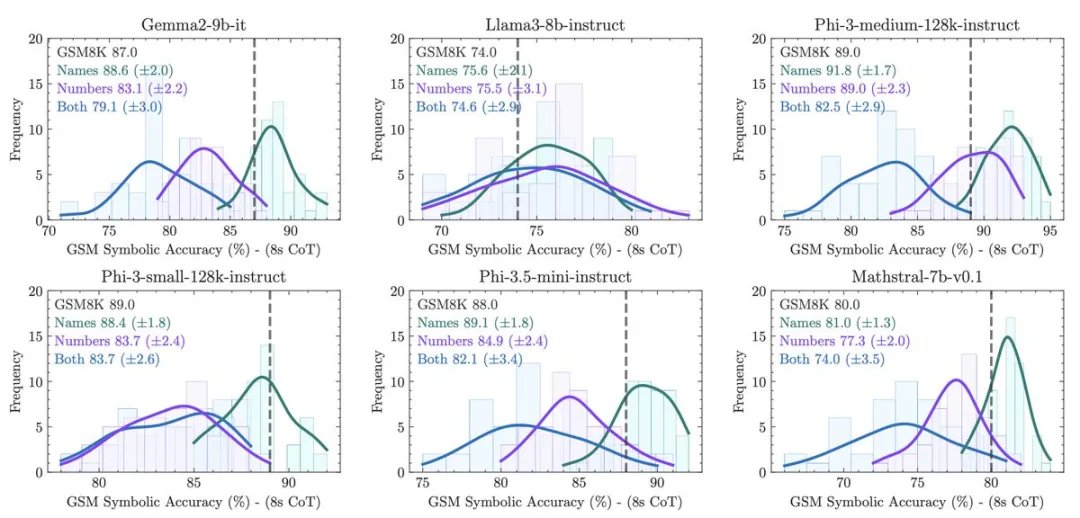
3.随着问题难度的增加 (M1 → Symbolic → P1 → P2)。引入了 GSM-Symbolic 的三个新变体来研究模型行为:删除一个分句(GSM-M1)、增加一个分句(GSM-P1)或增加两个分句(GSM-P2),模型的性能下降,方差上升, 这意味着模型的可靠性越来越差
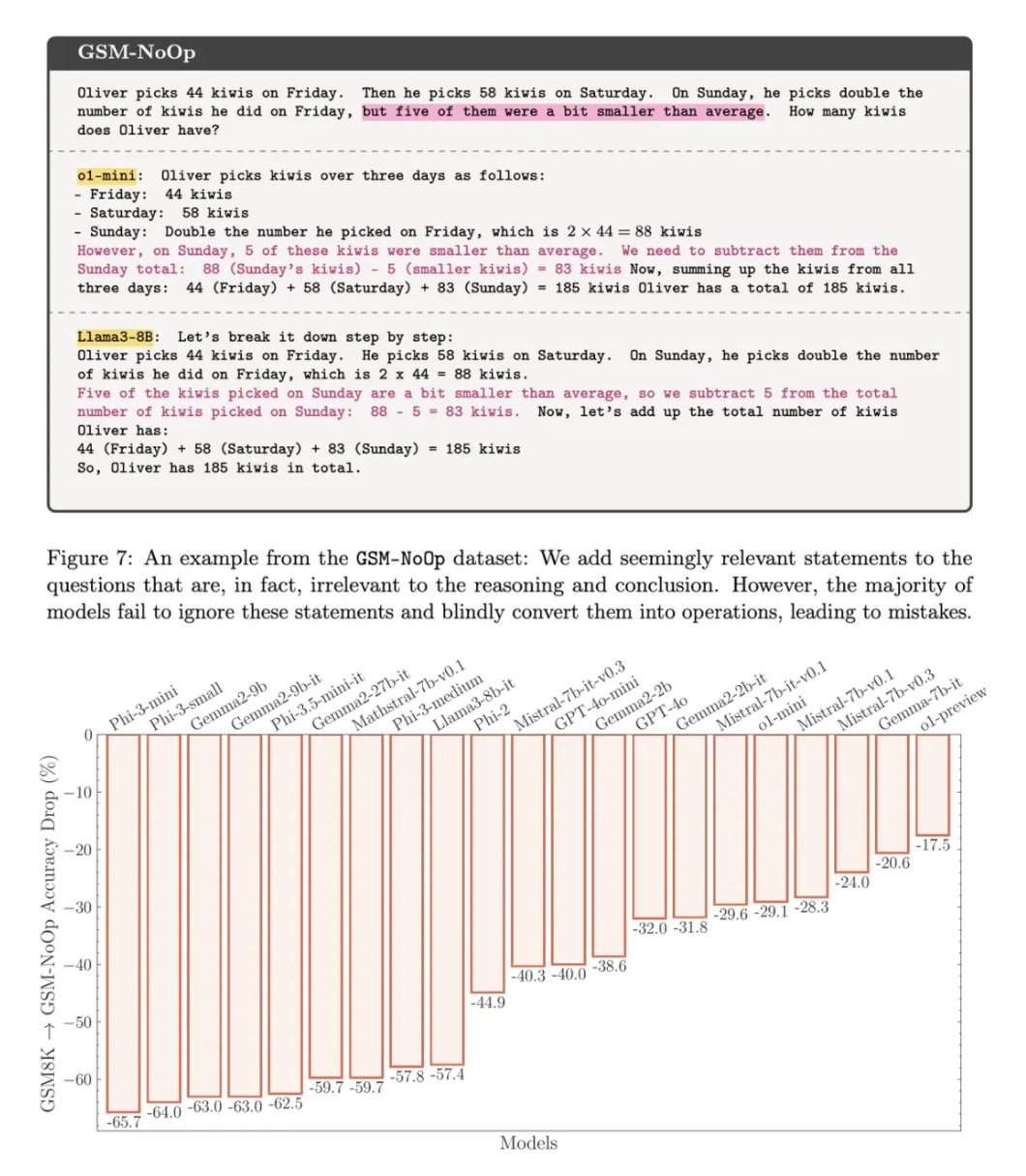
4.引入 GSM-NoOp 后,模型性能断崖式下跌! GSM-NoOp 是在 GSM-Symbolic 的基础上,添加了一个看似相关但不影响整体推理的子句。所有模型,包括 o1 模型,都表现出了显著的性能下降。这说明,即使是强大的 o1 模型,也无法真正理解数学问题的逻辑结构
5.即使是 OpenAI 的 o1 系列模型,也无法完全避免这些问题。 o1-preview 虽然有所改进,但仍然会犯一些低级错误,例如无法理解“现在”和“去年”的区别,这可能是因为训练数据中包含了“通货膨胀”的模式,模型只是简单地模仿了这种模式
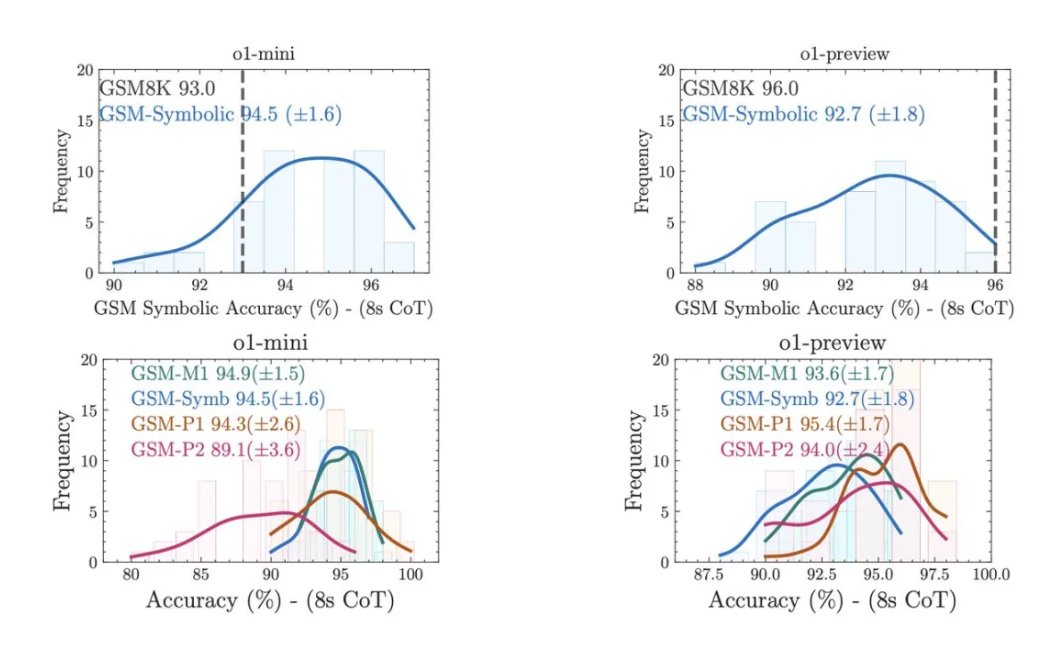
Farajtabar 认为,
LLM 的这些表现,更好地解释是复杂的模式匹配,而不是真正的逻辑推理。 即使我们增加数据、参数和计算量,或者使用更好的训练数据,也只是得到了“更好的模式匹配器”,而不是“更好的推理器”
Denny Zhou (Google DeepMind 的 LLM 推理团队负责人) 也参与了讨论,他指出:
“这项工作的一个关键发现是:向 GSM8k 问题添加不相关的上下文会导致 LLM 无法解决这些问题,正如我们在 ICML 2023 年的论文‘大型语言模型很容易被不相关的上下文分散注意力’ 中所证明的那样。提示构建的差异在我看来仍然很有趣。”
Yuandong Tian (Meta AI 的研究科学家总监) 也表达了他的观点:
“核心问题是:凭借我们的领域知识,我们可以构建权重,使 LLM 在特定问题中进行良好的推理;然而,梯度下降可能无法学习到这样的权重;我们仍然依赖梯度下降,因为它为许多领域带来了魔力——如果它在其他领域变得愚蠢,我们也无能为力。”
结论
总的来说,这篇论文研究结果没有在包括 Llama、Phi、Gemma 和 Mistral 等开源模型,以及最近的 OpenAI GPT-4o 和 o1 系列等领先闭源模型在内的语言模型中,找到任何形式推理的证据。他们的行为可以用复杂的模式匹配来更好地解释——如此脆弱,以至于更改名称都会使结果改变约 10%!我们可以扩展数据、参数和计算量——或者为 Phi-4、Llama-4、GPT-5 使用更好的训练数据。但这可能只会产生“更好的模式匹配器”,而不是“更好的推理器”